
程序的机器级表示_晨哥是个好演员的博客-CSDN博客_程序的机器级表示
【CSAPP-深入理解计算机系统】3-8.数组的分配和访问_哔哩哔哩_bilibili
Lecture 09 Machine Level Programming V Advanced Topics_哔哩哔哩_bilibili
数组、指针内存访问、
数组在内存中是一段连续的空间,至于其每个单元的地址间距,与其单个元素类型字长有关。指针在内存中的加一跳转与指针的类型有关,计算结果会根据该指针引用的数据类型进行伸缩,若指针是char类型,则地址单元是一个字节,每次加一仅跳转一个字节,若指针是int类型,则地址单元是四个字节,则每次加一跳转四个字节,如下图:

通常我们习惯于使用数组引用的方式来访问数组的元素,即使用 [] 运算符,也可以使用解引用运算符来访问。
int a[6] = { 0,1,2,3,4,5 };
a[1] = 1;
*(a+1) = 1;指针其实就是地址的抽象表述
二维数组的存放如下图所示:

二维数组可以理解成一个数组里的每一个元素都是一个一维数组。
int a[2][2] = {{1,2},{2,3,}};
// 在内存中存储顺序: 1 2 2 3二维数组在内存中是按照行优先的规则去存储的。
结构体和联合体、
在C/C++语言中,我们经常使用结构体struct或者class来表示复杂的数据结果,但是这些有猫腻,例如下面的两个class:
class A
{
public:
int a;
char b;
short c;
};
class B
{
public:
char a;
int b;
short c;
};
sizeof(A) = 8
sizeof(B) = 12明明是同样的数据成员,只是顺序不同,两个结构体的大小却不相同,相差了4个字节。为什么会这样?这就是字节对齐导致的问题。
字节对齐:现代计算机中,内存空间按照字节划分,理论上可以从任何起始地址访问任意类型的变量。但实际中在访问特定类型变量时经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序一个接一个地存放,这就是对齐,使用了空间换取效率的做法。
对齐的原因和作用:不同硬件平台对存储空间的处理上存在很大的不同。某些平台对特定类型的数据只能从特定地址开始存取,而不允许其在内存中任意存放。例如Motorola 68000 处理器不允许16位的字存放在奇地址,否则会触发异常,因此在这种架构下编程必须保证字节对齐。
但最常见的情况是,如果不按照平台要求对数据存放进行对齐,会带来存取效率上的损失。比如32位的Intel处理器通过总线访问(包括读和写)内存数据。每个总线周期从偶地址开始访问32位内存数据,内存数据以字节为单位存放。如果一个32位的数据没有存放在4字节整除的内存地址处,那么处理器就需要2个总线周期对其进行访问,显然访问效率下降很多。
因此,通过合理的内存对齐可以提高访问效率。为使CPU能够对数据进行快速访问,数据的起始地址应具有“对齐”特性。比如4字节数据的起始地址应位于4字节边界上,即起始地址能够被4整除。
此外,合理利用字节对齐还可以有效地节省存储空间。但要注意,在32位机中使用1字节或2字节对齐,反而会降低变量访问速度。因此需要考虑处理器类型。还应考虑编译器的类型。在VC/C++和GNU GCC中都是默认是4字节对齐,VS中默认对齐是8。
对齐的准则主要基于Intel X86架构介绍结构体对齐和栈内存对齐,位域本质上为结构体类型。对于Intel X86平台,每次分配内存应该是从4的整数倍地址开始分配,无论是对结构体变量还是简单类型的变量。
在C语言中,结构体是种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构体、联合等)的数据单元。编译器为结构体的每个成员按照其自然边界(alignment)分配空间。各成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。字节对齐的问题主要就是针对结构体。
结构体的对齐规则
(1)第一个成员在相比于结构体变量存储起始位置偏移量为0的地址处。
(2)从第二个成员开始,在其自身对齐数的整数倍开始存储(对齐数=编译器默认对齐数和成员字节大小的最小值,VS编译器默认对齐数为8)。
(3)结构体变量所用总空间大小是成员中最大对齐数的整数倍。
(4)当遇到嵌套结构体的情况,嵌套结构体对齐到其自身成员最大对齐数的整数倍,结构体的大小为当下成员最大对齐数的整数倍。
深入理解对齐的原理去看看这篇文章! C语言字节对齐问题详解 - clover_toeic - 博客园 (cnblogs.com)
研究B的对齐:
class B
{
public:
char b;
int a;
short c;
};
假设B从地址空间0x0000开始存放,且指定对齐值默认为8(8字节对齐),B中最大对齐数是4,因此B的大小是4的倍数。成员变量b的自身对齐值是1,比默认指定对齐值8小,所以其有效对齐值为1,其存放地址0x0000符合0x0000%1=0。成员变量a自身对齐值为4,所以有效对齐值也为4,只能存放在起始地址为0x0004~0x0007四个连续的字节空间中,0x0001~0x0003不符合对齐规则,不存放。变量c自身对齐值为 2,所以有效对齐值也是2,可存放在0x0008~0x0009两个字节空间中,符合0x0008%2=0。所以从0x0000~0x0009存放的都是B内容。由于结构体大小是4的倍数,因此多分配0x10~0x11两个字节,共计大小为12个字节。
之所以编译器在后面补充2个字节,是为了实现结构数组的存取效率。试想如果定义一个结构B的数组,那么第一个结构起始地址是0没有问题,但是第二个结构呢?按照数组的定义,数组中所有元素都紧挨着。如果我们不把结构体大小补充为4的整数倍,那么下一个结构的起始地址将是0x0000A,这显然不能满足结构的地址对齐。因此要把结构体补充成有效对齐大小的整数倍。其实对于char/short/int/float/double等已有类型的自身对齐值也是基于数组考虑的,只是因为这些类型的长度已知,所以他们的自身对齐值也就已知。
总结就是,结构体元素类型的排列顺序会影响其最终的结果,结构体内存对齐的设计也是为了提升寻址效率;相比于结构体的内存对齐,联合体的设计更加巧妙,并且节约空间,联合体中多个元素共享同一块地址空间。
栈帧、
栈帧:本质上是一种栈,只是这种栈专门用于保存函数调用过程中的各种信息(参数,返回地址,本地变量等)。栈帧有栈顶和栈底之分,其中栈顶的地址最低,栈底的地址最高。
ESP寄存器:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。
EBP寄存器:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
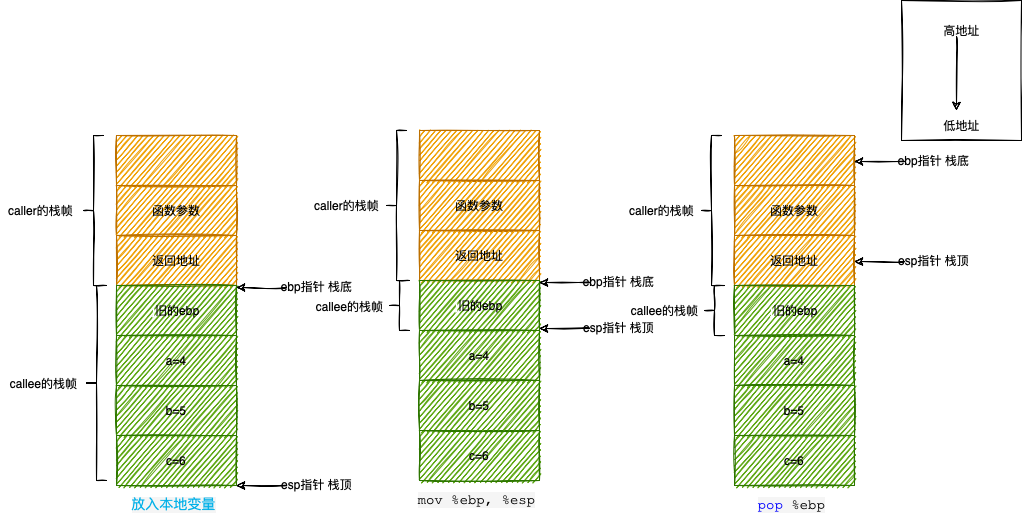
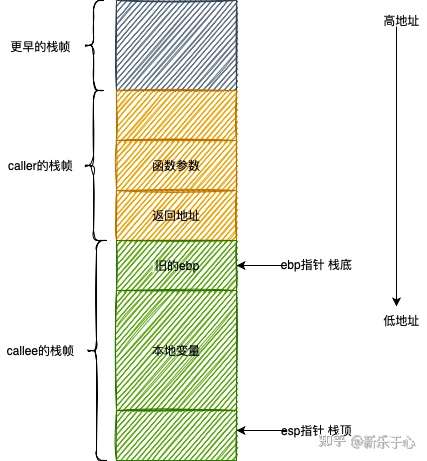
一般来说,我们将 %ebp 到 %esp 之间区域当做栈帧(也有人认为该从函数参数开始,不过这不影响分析)。并不是整个栈空间只有一个栈帧,每调用一个函数,就会生成一个新的栈帧。在函数调用过程中,我们将调用函数的函数称为“调用者(caller)”,将被调用的函数称为“被调用者(callee)”。在这个过程中,1)“调用者”需要知道在哪里获取“被调用者”返回的值;2)“被调用者”需要知道传入的参数在哪里,3)返回的地址在哪里。同时,我们需要保证在“被调用者”返回后,%ebp, %esp 等寄存器的值应该和调用前一致。因此,我们需要使用栈来保存这些数据。
缓冲区溢出、
计算机程序一般都会使用到一些内存,这些内存或是程序内部使用,或是存放用户的输入数据,这样的内存一般称作缓冲区。溢出是指盛放的东西超出容器容量而溢出来了,在计算机程序中,就是数据使用到了被分配内存空间之外的内存空间。而缓冲区溢出,简单的说就是计算机对接收的输入数据没有进行有效的检测(理想的情况是程序检查数据长度并不允许输入超过缓冲区长度的字符),向缓冲区内填充数据时超过了缓冲区本身的容量,而导致数据溢出到被分配空间之外的内存空间,使得溢出的数据覆盖了其他内存空间的数据。
缓冲区溢出是指计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。理想的情况是:程序会检查数据长度,而且并不允许输入超过缓冲区长度的字符。但是绝大多数程序都会假设数据长度总是与所分配的储存空间相匹配,这就为缓冲区溢出埋下隐患。操作系统所使用的缓冲区,又被称为“堆栈”,在各个操作进程之间,指令会被临时储存在“堆栈”当中,“堆栈”也会出现缓冲区溢出。
所谓缓冲区可以更抽象地理解为一段可读写的内存区域,缓冲区攻击的最终目的就是希望系统能执行这块可读写内存中已经被蓄意设定好的恶意代码。按照冯·诺依曼存储程序原理,程序代码是作为二进制数据存储在内存的,同样程序的数据也在内存中,因此直接从内存的二进制形式上是无法区分哪些是数据哪些是代码的,这也为缓冲区溢出攻击提供了可能。
当然,随便往缓冲区中填东西造成它溢出一般只会出现分段错误(Segmentation fault),而不能达到攻击的目的。最常见的手段是通过制造缓冲区溢出使程序运行一个用户shell,再通过shell执行其它命令。如果该程序属于root且有suid权限的话,攻击者就获得了一个有root权限的shell,可以对系统进行任意操作了。
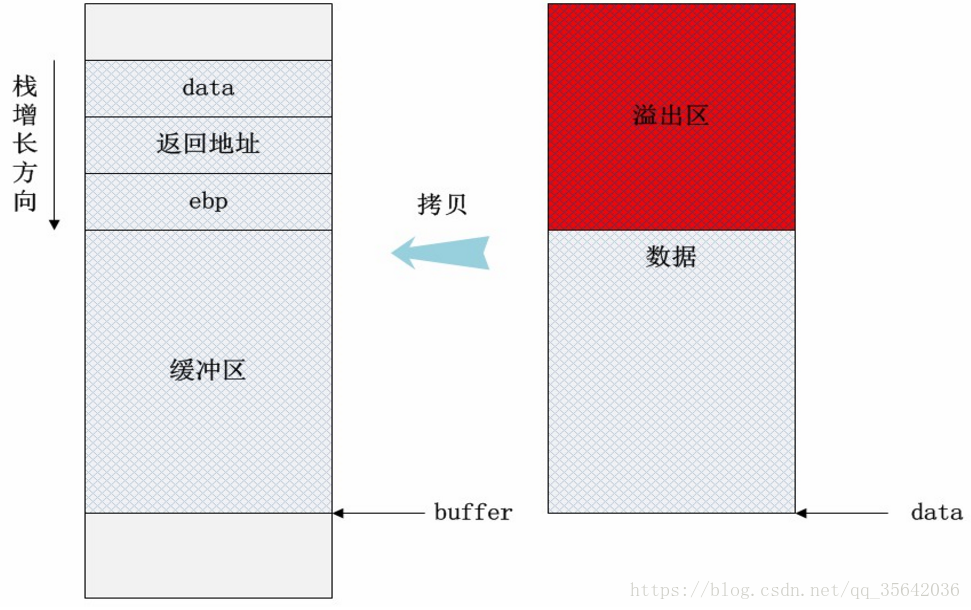
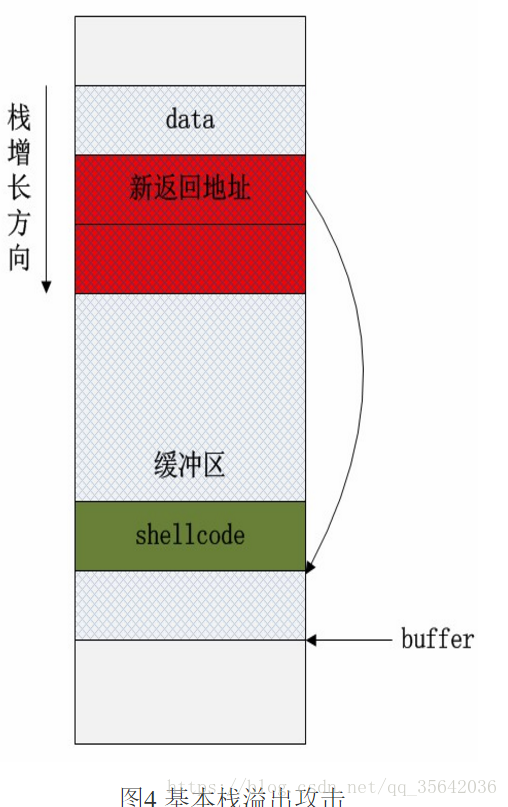
由于栈是低地址方向增长的,因此局部数组buffer的指针在缓冲区的下方。当把data的数据拷贝到buffer内时,超过缓冲区区域的高地址部分数据会“淹没”原本的其他栈帧数据,根据淹没数据的内容不同,可能会有产生以下情况:
1、淹没了其他的局部变量。如果被淹没的局部变量是条件变量,那么可能会改变函数原本的执行流程。这种方式可以用于破解简单的软件验证。
2、淹没了ebp的值。修改了函数执行结束后要恢复的栈指针,将会导致栈帧失去平衡。
3、淹没了返回地址。这是栈溢出原理的核心所在,通过淹没的方式修改函数的返回地址,使程序代码执行“意外”的流程!
4、淹没参数变量。修改函数的参数变量也可能改变当前函数的执行结果和流程。
5、淹没上级函数的栈帧,情况与上述4点类似,只不过影响的是上级函数的执行。当然这里的前提是保证函数能正常返回,即函数地址不能被随意修改(这可能很麻烦!)。 如果在data本身的数据内就保存了一系列的指令的二进制代码,一旦栈溢出修改了函数的返回地址,并将该地址指向这段二进制代码的其他位置,那么就完成了基本的溢出攻击行为。
缓冲区溢出举例、
void echo()
{
char buf[4]; /*buf故意设置很小*/
gets(buf);
puts(buf);
}
void call_echo()
{
echo();
}反汇编如下:
/*echo*/
000000000040069c <echo>:
40069c:48 83 ec 18 sub $0x18,%rsp /*0X18 == 24,分配了24字节内存。计算机会多分配一些给缓冲区*/
4006a0:48 89 e7 mov %rsp,%rdi
4006a3:e8 a5 ff ff ff callq 40064d <gets>
4006a8:48 89 e7 mov %rsp,%rdi
4006ab:e8 50 fe ff ff callq 400500 <puts@plt>
4006b0:48 83 c4 18 add $0x18,%rsp
4006b4:c3 retq
/*call_echo*/
4006b5:48 83 ec 08 sub $0x8,%rsp
4006b9:b8 00 00 00 00 mov $0x0,%eax
4006be:e8 d9 ff ff ff callq 40069c <echo>
4006c3:48 83 c4 08 add $0x8,%rsp
4006c7:c3 retq在这个例子中,我故意把buf设置的很小,且理论上只能输入3个字符,因为最为一个字符为‘\0'。运行该程序,我们在命令行中输入012345678901234567890123,24个字符,程序立马就会报错:Segmentation fault,我在VS上只要输入超过3个字符就报错了,VS对于安全还是很有保证的。
要想明白为什么会报错,我们需要通过分析反汇编来了解其在内存是如何分布的。如下图所示,此时计算机为buf分配了24字节空间,其中20字节还未使用。
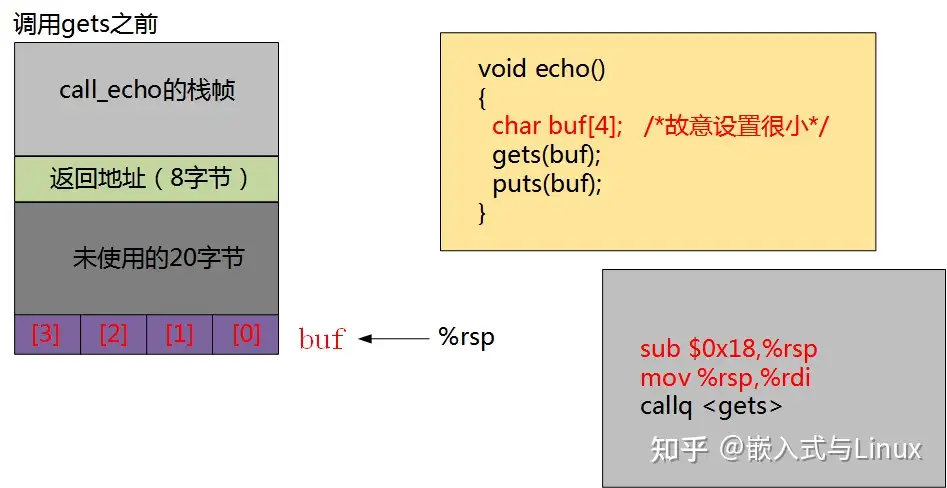
此时,准备调用echo函数,将其返回地址压栈。
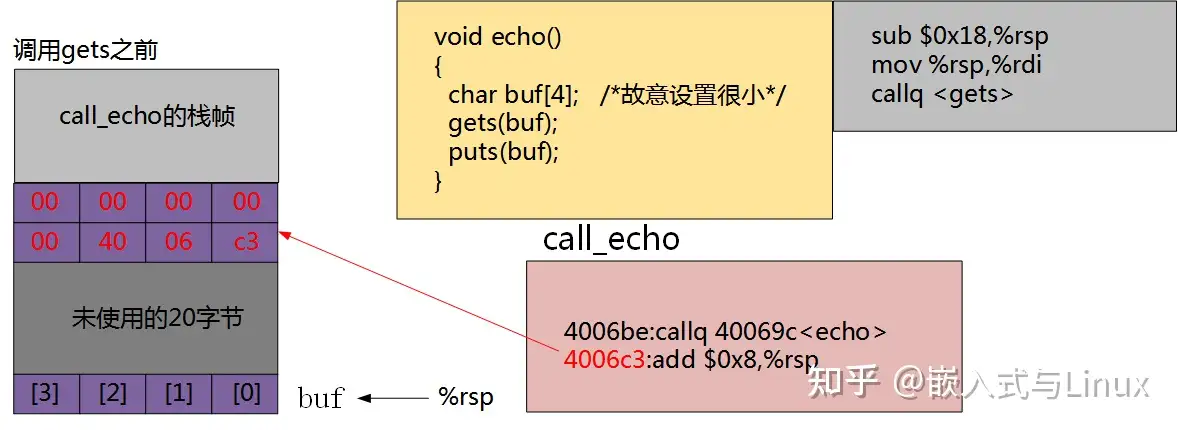
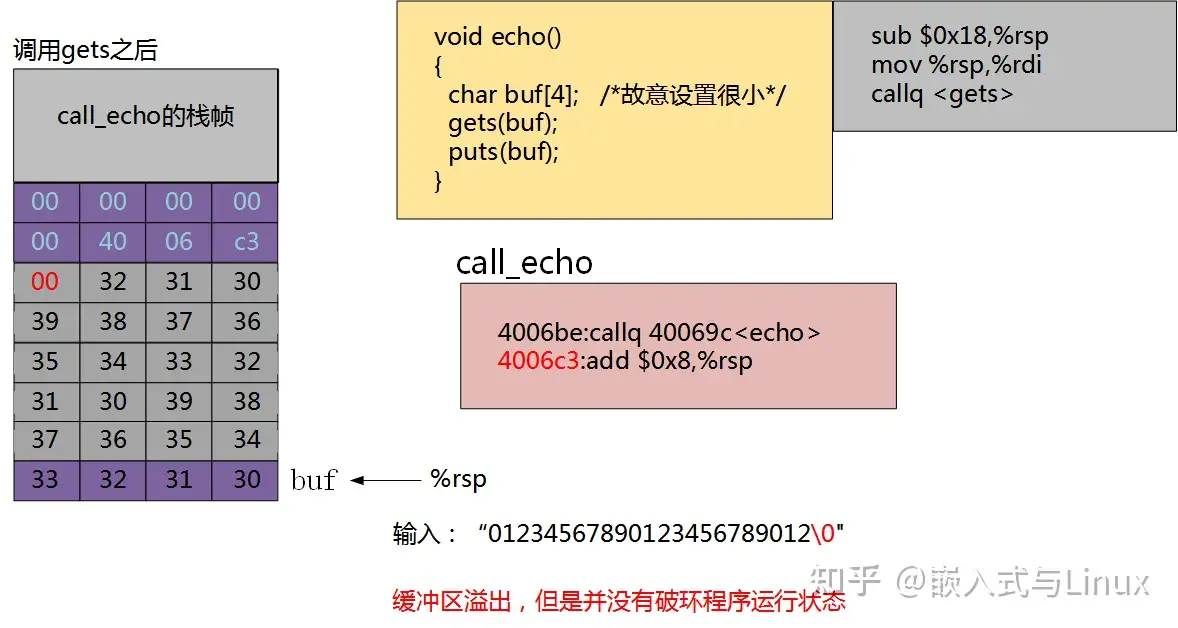
当我们输入“0123456789012345678 9012"时,缓冲区已经溢出,但是并没有破坏程序的运行状态。
当我们输入:“012345678901234567 890123"。缓冲区溢出,返回地址被破坏,程序返回 0x0400600。
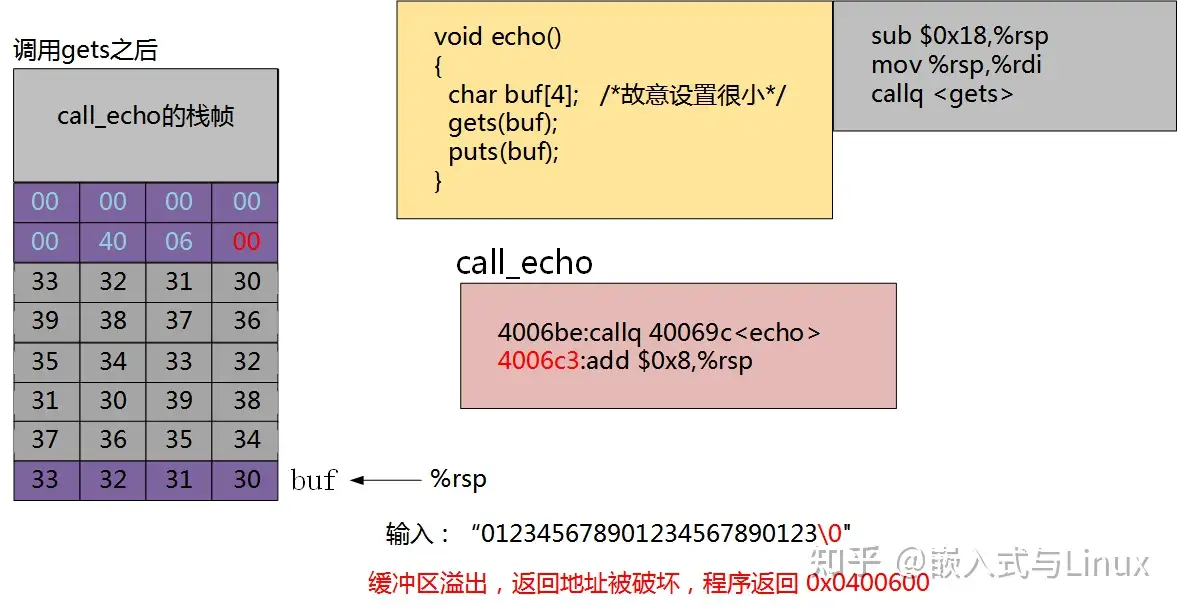
这样程序就跳转到了计算机中其他内存的位置,很大可能这块内存已经被使用。跳转修改了原来的值,所以程序就会中止运行。
黑客可以利用这个漏洞,将程序精准跳转到其存放木马的位置(如nop sled技术),然后就会执行木马程序,对我们的计算机造成破坏。
避免缓冲区溢出的三种方法、
为了在系统中插入攻击代码,攻击者既要插入代码,也要插入指向这段代码的指针。这个指针也是攻击字符串的一部分。产生这个指针需要知道这个字符串放置的栈地址。在过去,程序的栈地址非常容易预测。对于所有运行同样程序和操作系统版本的系统来说,在不同的机器之间,栈的位置是相当固定的。因此,如果攻击者可以确定一个常见的Web服务器所使用的栈空间,就可以设计一个在许多机器上都能实施的攻击。
1、栈随机化ASLR
栈随机化的思想使得栈的位置在程序每次运行时都有变化。因此,即使许多机器都运行同样的代码,它们的栈地址都是不同的。实现的方式是:程序开始时,在栈上分配一段0 ~ n字节之间的随机大小的空间,例如,使用分配函数alloca在栈上分配指定字节数量的空间。程序不使用这段空间,但是它会导致程序每次执行时后续的栈位置发生了变化。分配的范围n必须足够大,才能获得足够多的栈地址变化,但是又要足够小,不至于浪费程序太多的空间。
int main()
{
int a = 0;
cput << &a <<endl;
return 0;
}这段代码只是简单地打印出main函数中局部变量的地址。在32位 Linux上运行这段代码10000次,这个地址的变化范围为0xff7fc59c到0xffffd09c,范围大小大约是2的23次方。在64位 Linux机器上运行,这个地址的变化范围为0x7fff0001b698到0x7ffffffaa4a8,范围大小大约是2的32次方。
经过我在VS上的多次测试,定义在全局的变量的地址不会改变,new出来的变量和局部变量都是随机的。
其实,一个好的黑客专家,可以使用暴力破坏栈的随机化。对于32位的机器,我们枚举2 ^15 = 32768 个地址就能猜出来栈的地址。对于64位的机器,我们需要枚举2 ^24 = 16777216 次。如此看来,栈的随机化降低了病毒或者蠕虫的传播速度,但是也不能提供完全的安全保障。
2、检测栈是否被破坏
计算机的第二道防线是能够检测到何时栈已经被破坏。当访问缓冲区越界时,会破坏程序的运行状态。在C语言中,没有可靠的方法来防止对数组的越界写。但是,我们能够在发生了越界写的时候,在造成任何有害结果之前,尝试检测到它。
GCC在产生的代码中加人了一种栈保护者机制,来检测缓冲区越界。其思想是在栈帧中任何局部缓冲区与栈状态之间存储一个特殊的金丝雀( canary)值,如下图所示:
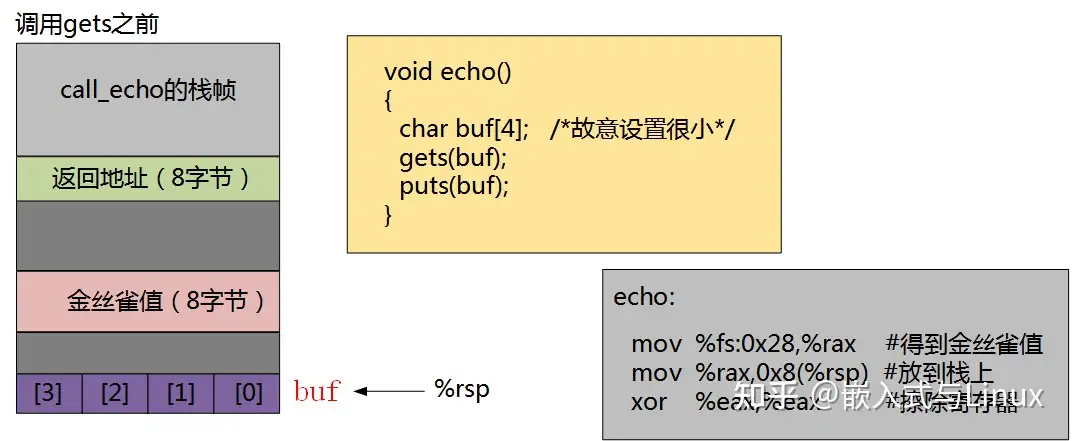
这个金丝雀值,也称为哨兵值,是在程序每次运行时随机产生的,因此,攻击者很难猜出这个哨兵值。在恢复寄存器状态和从函数返回之前,程序检查这个金丝雀值是否被该函数的某个操作或者该函数调用的某个函数的某个操作改变了。如果是的,那么程序异常中止。
3、限制可执行代码区域
最后一招是消除攻击者向系统中插入可执行代码的能力。一种方法是限制哪些内存区域能够存放可执行代码。在典型的程序中,只有保存编译器产生的代码的那部分内存才需要是可执行的。其他部分可以被限制为只允许读和写。
许多系统都有三种访问形式:读(从内存读数据)、写(存储数据到内存)和执行(将内存的内容看作机器级代码)。以前,x86体系结构将读和执行访问控制合并成一个1位的标志,这样任何被标记为可读的页也都是可执行的。栈必须是既可读又可写的,因而栈上的字节也都是可执行的。已经实现的很多机制,能够限制一些页是可读但是不可执行的,然而这些机制通常会带来严重的性能损失。
4、使用安全的函数
如果要读取一个字符串应该要使用fgets()或者get_s()函数,它们的参数中都有限制读取的字符数量。使用scanf_s()还有strcpy_s()的安全的函数,而且在使用数组的时候要判断是否超出了数组的边界,使用assert()来断言判断。
总结
计算机提供了多种方式来弥补我们犯错可能产生的严重后果,但是最关键的还是我们尽量减少犯错。在数组中,我们可以将数组的索引声明为size_t类型,从根本上防止它传递负数。还有检测数组的索引值范围等等。总之,要养成良好的编程习惯,这样可以节省很多宝贵的时间。
Comments NOTHING