
万维网和超文本传输协议、
一提到互联网,我们首先映入脑海的很可能是万维网(World Wide Web, Web),虽然它霸占了我们绝大多数的网络体验(移动端应用也是基于Web技术的),但万维网不等于网络,它只是互联网上的一个庞大的应用而已。而支撑这个庞然大物重要的应用层协议之一便是超文本传输协议(Hypertext Transfer Protocol, HTTP)。
网页组成、
在开始介绍HTTP之前,我们需要先了解平时使用浏览器浏览的网页究竟是什么。网页是由一组文件构成的,这些文件可以是超文本标记语言(Hypertext Makeup Language, HTML)文件、图片、可交互程序、视频等等,大部分的网页都由一个基础的HTML文件加上被这个文件引用的其他文件构成。
基础HTML文件通过网址(Uniform Resource Locator, URL)引用其他文件,我们也通过网址来访问网站。网址可以视作万维网中的地址,浏览器使用这些地址来找到需要的网页,而网址实际上和ip地址有千丝万缕的关系,这一关系会在介绍域名系统(Domain Name Systeam, DNS)的部分详细介绍。下面展示了一个典型的网址:
http://www.someschool.edu/someDepartment/picture.gif
网址的结构很简单,它由服务器名称(hostname)和路径组成,服务器名称指定需要访问的服务器,而路径则指定这一文件在服务器文件系统中的位置。在上面这个网址中,www.someschool.edu是服务器名称,someDepartment/picture.gif是文件路径。
HTTP总览、
HTTP这一应用层协议是基于TCP的,也就是说任何想使用HTTP的应用都必须选择TCP作为传输层协议。我们还是以浏览器为例,当用户在浏览器中点击了一个超链接或者在网址栏中输入了网址点击访问时,浏览器所在的主机就会向网址中指定的服务器发出TCP连接请求,当主机和服务器建立了TCP连接后,主机接着向服务器请求网址中指定的文件路径对应的文件,服务器在收到文件路径之后在本地存储中找到这个文件并打包发送给主机,主机收到文件后便按照一定的逻辑将它显示在屏幕上,这就是我们访问一个网页的全过程。
HTTP协议中不要求客户端或者服务器任何一方保存关于通信的另一方的任何信息,例如一个主机如果在几秒内多次向服务器请求同一个文件,服务器并不会因为之前已经发送过相同的文件而做出不一样的响应,相反,服务器完全不记得之前给这个主机发送过相同的文件这件事,它只会和之前一样忠实地履行协议,将相同的文件多次发送出去。因为这种特性,所有http被称为是无状态协议。
持续\非持续连接、
我们上面提到了HTTP是基于TCP的,并简单介绍了访问网页的过程,但是忽略了一个问题:何时关闭TCP连接?流行的TCP连接的管理方式有两种:传输一个文件就建立一个TCP连接;只建立一个TCP连接传输所有的文件。这两种方式就分别对应非持续连接(Non-persistent connections)和持续连接(Persistent connections),HTTP同时支持两种连接管理方式,大部分浏览器默认使用后者,但也可以调整为使用非持续连接。
让我们一步一步观察网页访问过程来对比两种方式,假设我们需要访问下面这个网址,它对应的网页由一个基础HTML文件和五个图片文件组成:
www.bilibili.com/home/home.index
当使用非持续连接时:
- 浏览器所在的主机找到服务器名称www.bilibili.com所对应的ip地址,浏览器进程通过端口80(预留给HTTP的默认端口)和主机建立TCP连接
- 主机向服务器发送HTTP请求信息,其中包含文件路径home/home.index
- 服务器通过接口收到请求信息,在本地存储中找到对应文件放入响应信息中交给接口
- 服务器请求关闭TCP连接,等待确认主机已经顺利接收到响应信息,如果主机没有接收到,则连接还不能关闭
- 主机接收到响应信息得到基础HTML文件,并发送信息告诉服务器可以关闭连接,连接关闭
- 主机解析该HTML文件发现它还引用了五个图片文件,于是重复五遍上述步骤以此得到这五个图片文件
对于一个由六个文件组成的网页来说,主机需要和服务器建立六个TCP连接来获得全部文件。但上面的步骤不一定是完全按顺序进行的,浏览器可能并行地和服务器建立多个连接来提升访问速度。如今的大多数浏览器默认会同时维护五到十个TCP连接。
为了更方便地衡量访问网页所需的时间,我们将以时间为单位的延迟抽象成来回通信时间(Round-Trip Time, RTT),一次来回通信时间所对应的时长就是从发送信号方发送信号到接收信号方发送的响应信号到达发送信号方所耗费的时间:
对于非持续连接来说,每次接受一个文件都需要建立一个TCP连接,其中包含“三次握手”,前两次握手便耗费了一次来回通信时间,在最后一次握手时,浏览器所在的主机发送的TCP回应信息可以同时包含HTTP请求信息,于是服务器接收到TCP回应信息成功建立TCP连接的同时也接收到了HTTP请求信息,于是发送对应的文件给主机。整个请求单个文件的过程耗费了两次来回通信时间:
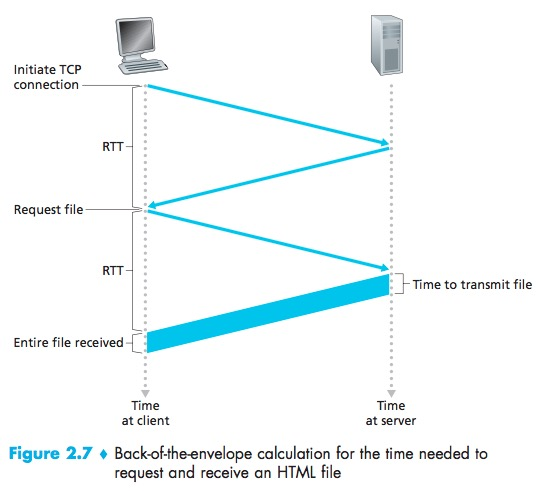
非持续连接每一次建立TCP连接都会消耗额外的时间(每次建立连接都需要一次来回通信时间)以及服务器的资源(TCP缓冲区、端口等等),相比较而言,持续连接使用一个TCP连接来完成一个网页所有文件的传输,节省了时间和资源。持续连接会自动关闭持续一段时间闲置的TCP连接。
HTTP信息格式、
请求信息(HTTP request message):
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/5.0
Accept-language: fr- 这个请求信息只有五行,其中第一行是请求行(request line),剩下四行都是请求头(header lines)。
- 请求行在请求信息格式中只有一行,分为三个部分:请求方法、网址中的文件索引和使用的HTTP版本。
- 接下来的Host就是服务器名称;Connection: close告诉服务器使用非持续连接,在发送完请求行中指定的文件后就关闭TCP连接;
- User-agent告诉服务器发送这个请求的浏览器是什么版本,上述例子中的Mozilla/5.0对应FireFox浏览器;
- Accept-language告诉服务器用户希望获得什么语言版本的文件,如果没有这个版本的文件,则服务器发送默认的语言版本。
HTTP中还有很多本地化相关的请求头。下面是HTTP请求信息的格式:

可以看到,HTTP中所有的行都是以一个回车符和一个换行符结尾的,并且在头部信息的最后一行下面还有空白的一行。接下来的Entity body使用与否和请求方法有关,GET方法并不使用这个信息域。
HTTP中的请求方法只有GET, POST, HEAD, PUT和DELETE这五种,下面分别介绍这五种请求方法:
- GET方法是最常用的请求方法,它用于向服务器请求请求行中文件索引对应的文件,在使用GET方法时,Entity body为空
- POST方法和GET方法功能基本相同,但它用于带输入的HTTP请求,例如用户在搜索引擎中搜索某样东西时,输入的搜索关键字就存储在Entity body中。注意,带输入的HTTP请求并不是只能使用POST方法,我们一样可以使用GET方法来完成类似搜索的功能,这是通过在网址末添加搜索关键字中完成的。例如当我们访问谷歌时,网址为https://www.google.com.hk,然后我们在输入框中输入"HTTP"并进行搜索,此时访问的网址就会变成https://www.google.com.hk/search?q=HTTP(实际上的网址可能很长)
- HEAD方法也是请求一个文件,但是它要求响应信息中只包含信息头,这一方法通常用于开发调试
- PUT用于将文件放入特定的服务器中,文件内容在Entity body中
- DELETE用于删除服务器中的特定文件
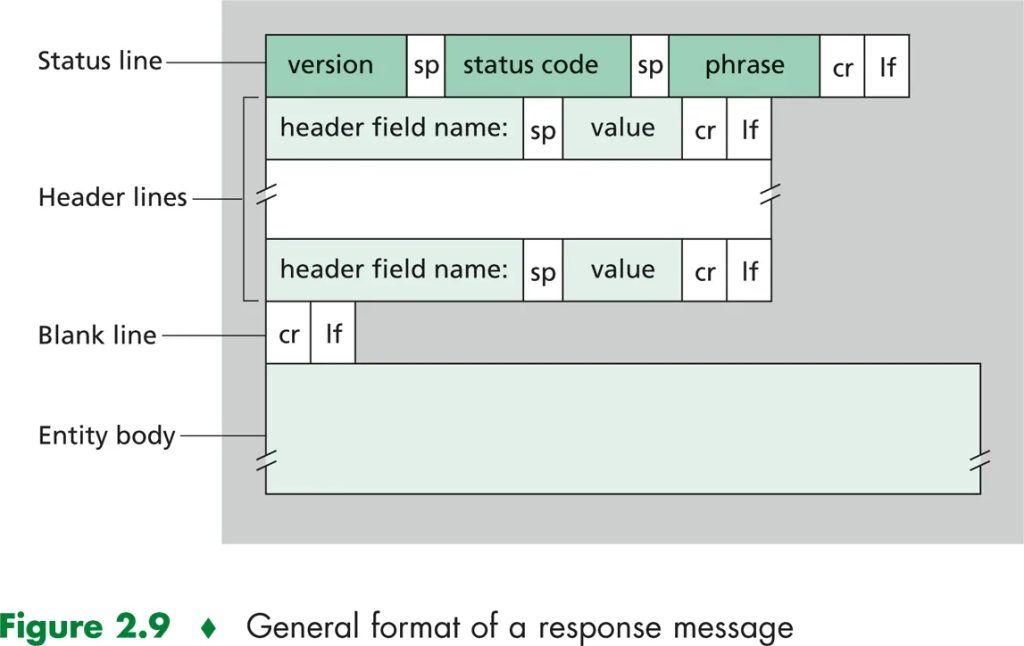
响应信息(HTTP respond message):
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data data data ......)- 类似请求信息,响应信息的第一行被称为状态行(status line),剩下的六行都是响应头(header line),状态头分为三个部分:HTTP版本、状态码和与之对应的状态信息,例子中的状态码为200,状态信息为OK,意味着一切正常,浏览器可以顺利得到请求的文件。
- 接下来的Connection: close告诉浏览器服务器将要关闭这个TCP连接;
- Date表明了这个响应信息被创建的时间,而不是响应信息中的文件被创建或者上一次修改的时间;
- Server和请求信息中的User-agent类似,告诉浏览器创建这个响应信息的服务器版本;
- Last-Modified是响应信息中的文件被创建或者上一次修改的时间;
- Content-Length是响应信息中的文件的大小,单位是byte;
- Content-Type表明相应信息中文件的类型,在这里是html文本文件;最后的(data ...)就代表响应信息中的文件。
响应信息的结构如下所示:
下面介绍一些常见的状态码和状态信息组合:
- 200 OK: 请求成功
- 301 Moved Permanently: 请求的文件已经被永久移动到其他位置,服务器会将新位置放在响应信息中的Location响应头中,浏览器会据此自动发起第二次请求
- 400 Bad Request: 一个非常宽泛的错误码,表示服务器无法理解请求信息
- 404 Not Found: 服务器中无法找到请求的文件
- 505 HTTP Version Not Supported: 服务器不支持请求信息指定的HTTP版本
Cookies、
前面提到,Web服务器是不会保存客户端的信息的,这是出于性能的考虑才这么设计的。但是随着互联网发展,网页逐渐有了识别不同用户的需求,识别不同用户就可以进一步提供更好的个性化服务。Cookies技术就是识别用户的技术之一,它将cookie信息保存在客户端本地,在需要时发送给服务器来让服务器,服务器再通过其维护的数据库来识别不同用户,cookie信息可以看作服务器中数据库里的用户信息索引。
cookie提供多项有用的功能,它使Web服务器能够在客户端上保存用户在网站上的行为(比如添加购物车),跟踪用户的浏览活动(点击特定链接、登录);它还使浏览器能够保存用户在表单中输入的信息,例如登陆用的用户名和密码等,方便用户使用。
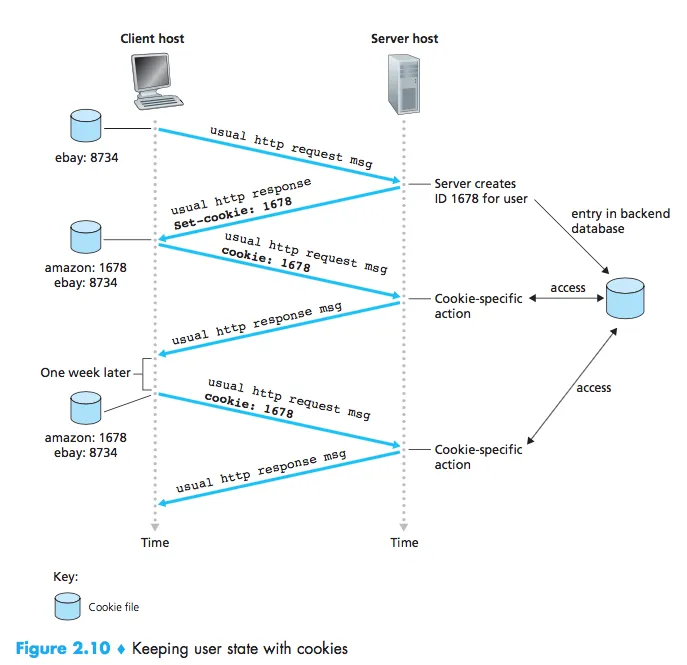
下面我们来看一个使用cookie的具体例子。Susan是ebay的忠实用户,经常使用ebay进行网上购物,但她今天第一次使用Amazon。当她访问Amazon的请求到达服务器之后,Amazon的服务器会识别到这个主机在数据库中没有对应的用户信息,随后它会在数据库中新增一个条目,对应一个新的索引值。随后服务器将这个索引值放入响应信息中发给Susan的电脑,这个索引值可能是这样的:
Set-cookie: 1678Susan的浏览器在响应信息中发现这一行之后,就将这个值放入其维护的cookie文件中,对应Amazon这个网站。在Susan后续访问Amazon时,浏览器都会在其维护的cookie文件中寻找Amazon对应的cookie值并插入请求信息中,于是在浏览器发送的每个请求信息在请求头中都有这样一行(只要她没有清空cookie记录):
Cookie: 1678
而每次Susan在Amazon网站上的行为都可以被Amazon的服务器记录到1678对应的条目中(想想或许有点可怕),这样Susan就能从Amazon网站上获得更加个性化的服务,而Amazon也有办法从Susan那里赚更多钱了。当Susan在Amazon网站上注册了一个新的帐号之后,服务器中匿名的cookie条目就会和这个帐号的条目合并。上述cookie的运作过程图示如下:
网页缓存(Web Caching)和CDN技术、
网页缓存技术和CDN加速技术有一定的相关性,但不能完全等同。网页缓存技术是指在客户端和服务器端间通过缓存机制,使得客户端在请求某个网页时,可以从本地的缓存中或者代理服务器的缓存中读取到该网页的副本,而不必重复从服务器读取。这样可以减少网络流量,提高请求速度。
而CDN加速则是通过在网络中增加一层代理服务器,使得用户请求能够从最近的服务器节点读取数据,从而缩短请求延迟时间和提高请求带宽。在CDN中缓存的数据通常也会进行网页缓存,以更快地响应用户请求。
网页缓存技术主要用于缓存频繁访问的Web页面,以减少从原服务器获取内容的次数,从而提高网络性能和速度。
而CDN技术,也称内容分发网络,主要用于把内容分布到全球多个地点,并通过代理服务器进行分发。CDN的目的是通过减少访问者与服务器的网络距离,从而提高网页加载速度和提供更好的用户体验。
因此,网页缓存技术和CDN技术的作用是类似的,但不完全相同。网页缓存技术更多地关注的是缓存页面,而CDN技术则关注的是降低网络距离以提高网页加载速度。因此,网页缓存技术是CDN加速的一部分,但不是CDN加速的全部。
网页缓存技术可以使用代理服务器来实现,也可以在服务器端或客户端直接实现。代理服务器可以在请求和响应之间缓存内容,以便在后续请求中快速回复,从而提高网页加载速度。但是,并不是所有的网页缓存技术都需要代理服务器,它也可以在客户端或服务器端实现。
缓存就是用于提升访问速度的存储数据的硬件或者软件组件。网页缓存,又名代理服务器(Proxy Server),指代替原Web服务器响应主机的请求信息的服务器,其通常由网络服务提供商(ISP)部署在距离主机更近的地方,可以提升附近这片区域访问网页的速度,至于网页缓存是如何做到这一点的,让我们看一个例子。假设我们想要访问 www.bing.com 这个网站:
- 浏览器首先和网页缓存服务器建立TCP连接,发出请求信息
- 网页缓存服务器在其存储中寻找这个请求信息对应的文件,如果找到了的话就发给浏览器
- 如果没有找到,则网页缓存服务器和原Web服务器建立TCP连接,接着请求浏览器所请求的文件,原Web服务器将文件放入响应信息中发回给网页缓存服务器
- 网页缓存服务器接收到响应信息,将其中的文件存储在本地内存中,然后再给浏览器以响应信息的形式发送一份拷贝,浏览器最终接收到响应信息

由于主机和网页缓存服务器的通信不需要经过互联网,而是在接入网内完成的,因此速度要比直接访问原Web服务器要快得多,并且由于显著地减少了接入网和互联网通信的流量,也变相提升了接入网的网络连接质量。
条件性GET(The Conditional GET)、
网页缓存甚好,但这一系统还有一个问题需要我们解决:存储在其中的文件可能过期。网页随时可能更新,当浏览器请求网页时,若网页缓存没有及时更新文件而把过期的文件传给了用户,那就是帮了倒忙,我们需要一个办法来更新网页缓存中的文件,这就是条件性GET.
还是来看一个例子,假设我们用浏览器访问www.exotiquecuisine.com/fruit/kiwi.gif,浏览器向网页缓存请求这个文件,发生了缓存未命中,于是网页缓存接着向原Web服务器发出请求:
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.comWeb服务器发回响应信息:
HTTP/1.1 200 OK
Date: Sat, 3 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
Last-Modified: Wed, 9 Sep 2015 09:23:24
Content-Type: image/gif
(data data data data data ...)网页缓存服务器将文件和最后修改时间Last-Modified一起存储在本地,然后再将拷贝放入响应信息发给浏览器。假设三周后浏览器又向网页缓存请求相同的文件,这时候网页缓存需要先确定本地存储中的文件是否过期,于是它向原Web服务器发送请求信息,其中请求方法为条件性GET:
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
If-modified-since: Wed, 9 Sep 2015 09:23:24If-modified-since是条件性GET中必须的一行请求头,其中值和三周前网页缓存接收到的响应信息中的Last-Modified中的值相同。在使用条件性GET时,只有文件在这个时间之后被修改过,服务器才会发送文件,否则如果该文件并没有被更新,服务器只会返回一个响应头:
HTTP/1.1 304 Not Modified
Date: Sat, 10 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
(empty entity body)网页缓存根据状态码304 Not Modified得知本地存储中的文件是最新的,于是将其拷贝放入响应信息中发给浏览器。
[root@CentOS_8 http_https]# curl -v -H "User-Agent: Mozilla/5.0" -H "If-modified-since: Wed, 9 Sep 2021 09:23:24 GMT" http://baidu.com
* Rebuilt URL to: http://baidu.com/
* Trying 39.156.66.10...
* TCP_NODELAY set
* Connected to baidu.com (39.156.66.10) port 80 (#0)
> GET / HTTP/1.1
> Host: baidu.com
> Accept: */*
> User-Agent: Mozilla/5.0
> If-modified-since: Wed, 9 Sep 2021 09:23:24 GMT
>
< HTTP/1.1 304 Not Modified
< Date: Mon, 13 Feb 2023 01:50:57 GMT
< Server: Apache
< Connection: Keep-Alive
< ETag: "51-47cf7e6ee8400"
< Expires: Tue, 14 Feb 2023 01:50:57 GMT
< Cache-Control: max-age=86400
Comments NOTHING