
1.2 一个编译器的结构
编译器能够把源程序映射为语义上等价的目标程序,这个映射由两个部分组成:分析部分和综合部分。
分析(analysis)部分把源程序分解为多个组成要素,并在这些要素之上加上语法结构。然后它使用这个结构来创建该源程序的一个中间表示。如果分析部分检查出源程序没有按照正确的语法构成,或者语义上的不一致,它就必须提供有用的信息,使得用户可以按此进行改正。分析部分还会收集有关源程序的信息,并把信息存放在一个称为符号表(symbol table)的数据结构中。符号表将和中间表示形式一起传送到综合部分。
综合(synthesis)部分根据中间表示和符号表中的信息来构造用户期待的目标程序。分析部分经常被称为编译器的前端(front end),而综合部分称为后端(back end)。
如果我们更加详细的研究编译过程,会发现它顺序执行了一组步骤。每个步骤把源程序的一种表示方式转换成另一种表示方式。在实践中,多个步骤可能会被组合到一起,而这些组合在一起的步骤之间的中间表示不需要被明确的构造出来。存放这个源程序的信息的符号表可由编译器的各个步骤使用。
有些编译器在前端和后端之间有一个与机器无关的优化步骤。这个优化步骤的目的是在中间表示之上进行转换,以便后端程序能够生成更好的目标程序。如果基于未经过此优化步骤的中间表示来生成代码,则代码的质量会受到影响,因为优化是可选择的。
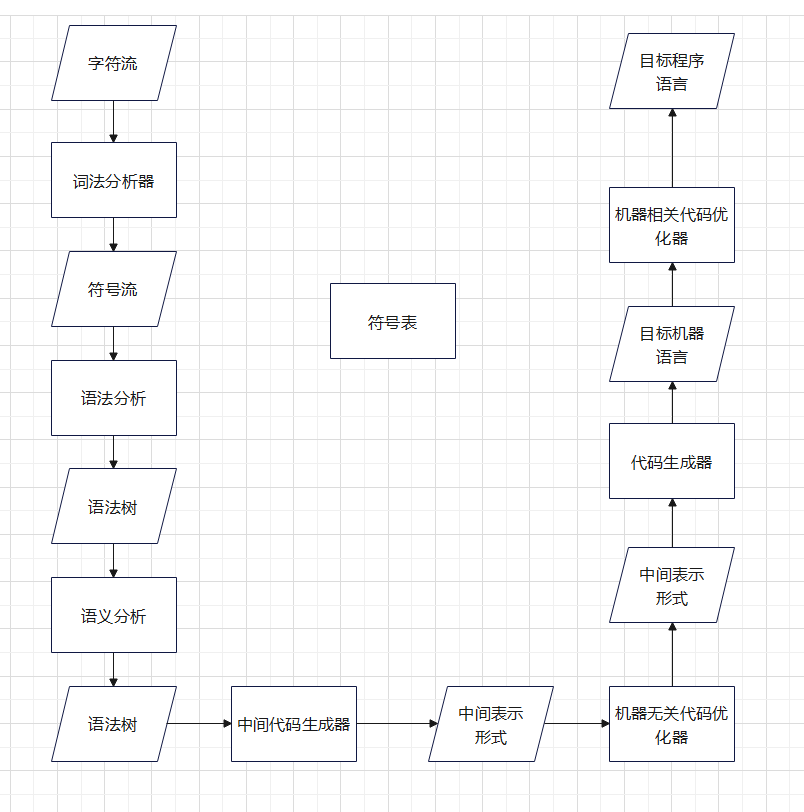
1.2.1 词法分析
编译器的第一个步骤称为词法分析或扫描。词法分析器读入组成源程序的字符流,并且将它们组织成为有意义的词素(lexeme)序列。对于每个词素,词法分析器产生如下形式的词法单元(token)进行输出。
< token-name, attribute-value>
这些词法单元被传送到下一个步骤,即语法分析。在这个词法单元中,第一个分量token-name是一个由语法分析步骤使用的抽象符号,而第二个分量attribute-value指向符号标志关于这个词法单元的条目。符号表条目的信息会被语义分析和代码生成步骤使用。
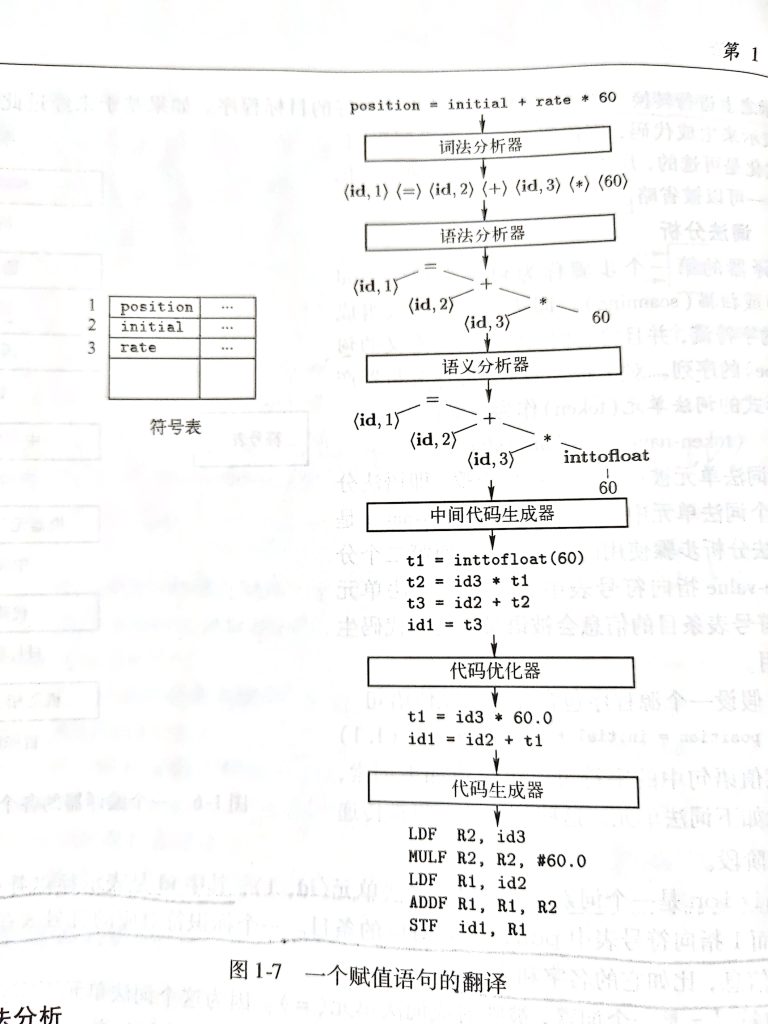
例如,假设一个源程序包含下列赋值语句:
position = initial + rate * 60;
这个赋值语句中的字符可以组合成为下列词素,并映射成为如下的词法单元。这些词法单元将被传递给词法分析阶段。
1)position是一个词素,被映射为词法单元<id,1>,其中id是表示标识符(identifier)的抽象符号,而1指向符号表中position对应的条目。一个标识符对应的符号表条目存放该标识符有关的信息,比如它的名字和类型。
2)赋值符号 = 是一个词素,被映射为词法单元<=>。因为这个词法单元不需要属性值,所有我们省略了第二个分量。也可以使用assign这样的抽象符号作为词法单元的名字,但是为了标记上的方便,我们选择词素本身作为抽象符号的名字。
3)initial是一个词素,被映射为词法单元<id,2>
4)+ 是一个词素,被映射为词法单元<+>
5)rate是一个词素,被映射为词法单元<id,3>
6)* 是一个词素,被映射为词法单元<*>
7)60是一个词素,被映射为词法单元<60>。这里从技术上来讲,我们应该为词素60建立一个形如<number,4>的词法单元,其中4指向符号表中对应与整数60的条目。但是我们要到第二章中才讨论数字的词法单元。
分割词素的空格会被词法分析器忽略掉!!!
经过词法分析后,赋值语句被表示成如下的词法单元序列:
<id,1> <=> <id,2> <+> <id,3> <*> <60>
1.2.2 语法分析
编译器的第二个步骤成为语法分析或解析(parsing)。语法分析器使用由词法分析器生成的各个词法单元的第一个分量来创建树形的中间表示。该中间表示给出了语法分析产生的词法单元流的结构。一个常用的表示方法是语法树(sytnax tree),书中的每个内部节点表示一个运算,而该节点的子节点表示该运算的分量。
上述图中的语法树显示了赋值语句中各个运算的运算顺序。这个运算顺序和通常的算术规则相同,即乘法的优先级大于加法,因此乘法应该在加法之前计算。
编译器的后续步骤使用这个语法结构来帮助分析源程序,并生成目标程序。
1.2.3 语义分析
语义分析器(semantic analyzer)使用语法树和符号表中的信息检查源程序是否和语言定义的语义一致。它同时也收集类型信息,并把这些信息存放在语法树或符号表中,以便在随后的中间代码生成过程中使用。
语义分析的一个重要部分是类型检查(type checking)。编译器检查每个运算是否具有匹配的运算分量。比如,很多程序设计语言的定义中要求一个数组的下标必须是整数。如果用一个浮点数作为数组下标,编译器就必须报告错误。有的语言可能允许某些类型转换,这被称为自动类型转换(coercion)。比如一个二元算术运算符可以应用于一对整数或者一对浮点数。如果应用于一个浮点数和一个整数,那么编译器会把整数转换为浮点数来进行运算。
上述图中语义分析器的类型检查程序发现运算符 * 被用于一个浮点数rate和一个整数60,这个情况下60被转换为一个浮点数60.0。额外节点inttofloat明确的把整数转换为一个浮点数。
1.2.4 中间代码生成
在把一个源程序翻译成目标代码的过程中,一个编译器可能构造出一个或多个中间表示,这些中间表示可以有多种形式,语法树就是一种中间表示形式,它们通常在语法分析和语义分析中使用。
在源程序的语义分析和语法分析完成之后,很多编译器生成一个明确的、低级的或类机器语言的中间表示。我们可以把这个表示看作是某个抽象机器的程序。该中间表示应该具有两个重要的性质,它应该易于生成并且能够被轻松的翻译为目标机器上的语言。
在后面的学习中,我们将考虑一种称为三地址代码的中间表示形式。这种中间表示由一组类似于汇编语言的指令组成,每个指令具有三个运算分量,每个运算分量都像一个寄存器。如上述图所示。
关于三地址指令,有几点是值得专门指出的。首先,每个三地址赋值指令的右部最多只有一个运算符,因为这些指令确定了运算完成的顺序,在源程序中,乘法应该在加法之前完成。第二,编译器应该生成个临时名字以存放一个三地址指令计算而得到的值,第三,有些三地址指令的运算分量少于三个。
1.2.5 代码优化
机器无关的代码优化步骤试图改进中间代码,以便生成更好的目标代码。更好通常意味着更快,但是也可能会有其他目标,如更短或能耗更低的目标代码。
比如,一个简单直接的算法会生成中间代码。使用一个简单的中间代码生成算法,然后再进行代码优化步骤,是生成优质目标代码的一个合理方法。优化器可以得出结论,把60从整数转换为浮点数的运算可以在编译期一劳永逸的完成。因此,用浮点数60.0来替代整数60就可以消除相应的intofloat运算。而且t3仅被使用一次,用来把它的值传递给id1。因此优化器可以把序列(1.3)转化为更短的指令序列。
不同的编译器所做的代码优化工作量相差很大,那些优化工作做的最多的编译器及所谓的优化编译器会在优化阶段花相当多的时间。有些简单的优化方法可以极大的提高目标程序的运行效率,而不会过多的降低编译的速度。
1.2.6 代码生成
代码生成器以源程序的中间表示形式作为输入,并把它映射到目标语言。如果目标语言是机器代码,那么就必须为程序使用的每个变量选择寄存器或内存位置,然后,中间指令被翻译成为能够完成相同任务的机器指令序列。代码生成的一个至关重要的方面就是合理分配寄存器以及存放变量的值。
如上图所示,优化后的代码被翻译成具有相同效果的汇编指令代码。
1.2.7 符号表管理
编译器的重要功能之一是记录源程序中使用的变量的名称,并收集和每个名称的各种属性有关的信息。这些属性可以提供一个名字的存储分配、它的类型、作用域等信息。对于这些名称,这些信息还包括它的参数数量和类型,每个参数的传递方法以及返回类型。
符号表数据结构为每个变量名字创建了一个记录条目,记录的字段就是名字的各个属性。这个数据结构应该允许编译器迅速查找到每个名字的记录,并向记录中快速存放和获取记录中的数据。
1.2.8 将多个步骤组合成趟
上述关于步骤的讨论讲的是一个编译器的逻辑组织方式。在一个特定的实现中,多个步骤的活动可以被组合成一趟,每趟读入一个输入文件,并产生一个输出文件。比如前端步骤中的词法分析、语法分析、语义分析以及中间代码生成可以被组合在一起成为一趟,代码优化可以作为一个可选的趟,然后可以有一个为特定目标机生成代码的后端趟。
有些编译器集合是围绕一组精心设计的中间表示形式而创建的。这些中间表示形式使得我们可以把特定语言的前端和特定目标机的后端相结合。使用这些集合,我们可以把不同的前端和某个目标机的后端结合起来,为不同的源语言建立该目标机上的编译器。类似的,我们可以把一个前端和不同的目标机后端结合,建立针对不同目标机的编译器。
常见计算机语言的分类
走向高级程序设计语言的重大一步发生在20世纪50年代的后五年。其间,用于科学计算的Fortran语言,用于商业数据处理的Cobol 语言和用于符号计算的Lisp语言被开发出来。
时至今日有几千种程序设计语言。可以通过不同的方式对这些语言进行分类:
方式之一是通过语言的代来分类。第一代语言是机器语言,第二代语言是汇编语言,而第三代语言是高级程序设计语言。第四代语言是为特定应用设计的语言,比如用于生成报告的NOMAD,用于数据库查询的SQL和用于文本排版的Postscript。术语第五代语言指的是基于逻辑和约束的语言,比如Prolog和0PS5。
另一种语言分类方式把程序中指明如何完成一个计算任务的语言的称为强制式(imperative)语言,而把程序中指明要进行哪些计算的语言称为声明式(declarative)语言。诸如C、C++、C#和Java等语言都是强制式语言。所有强制式语言中都有用于表示程序状态和语句的表示方法,这些语句可以改变程序状态。像ML、Haskell这样的函数式语言和Prolog这样的约束逻辑语言通常被认为是声明式语言。
冯·诺伊曼语言(von Neumann language)是指以冯·诺伊曼计算机体系结构为计算模型的程序设计语言。面向对象语言(object-oriented language)指的是支持面向对象编程的语言,脚本语言(scripting language)是具有高层次运算符的解释型语言。
Comments NOTHING