
词法分析是编译过程中的第一个阶段,也被称为扫描(Scanning)或词法扫描(Lexical Scanning)。它的主要任务是将输入的源代码字符串分解为一个个称为“词法单元”(Lexical Tokens)的最小语法单元,例如关键字、标识符、运算符、常量等。这些词法单元是编译器后续阶段进行语法分析和语义分析的基础。
具体来说,词法分析器执行以下任务:
- 识别词法单元: 词法分析器会根据语法规则,从源代码中识别出各种词法单元,如关键字(如if、while)、标识符(变量名)、运算符(+、-、*)、分隔符(逗号、分号)、常量(整数、浮点数、字符串)等。
- 忽略空白和注释: 词法分析器会忽略源代码中的空格、制表符、换行符等空白字符,以及注释,因为它们对语义没有直接影响。
- 错误处理: 词法分析器也负责检测和报告一些简单的词法错误,比如不符合规则的字符序列或未识别的字符。
- 生成词法单元流: 词法分析器将识别出的词法单元组织成一个流,供后续的语法分析阶段使用。这个流包含了源代码的基本构建块,有助于进一步理解代码的结构和含义。
词法分析使用有限自动机(Finite Automaton)。有限自动机是一种数学模型,用于描述和识别有限的状态集合、输入符号以及状态之间的转换规则。它可以有效地识别正则语言,这些语言可以用正则表达式来表示,而正则表达式常用于描述词法单元的模式。
在词法分析中,每个词法单元的模式可以用一个正则表达式来表示,而词法分析器则使用有限自动机来根据这些模式识别和生成词法单元。有限自动机可以分为两种主要类型:确定性有限自动机(DFA)和非确定性有限自动机(NFA)。在实际编译器实现中,通常会将正则表达式转化为等价的确定性有限自动机,以便高效地进行识别。
需要注意的是,虽然有限自动机在词法分析中广泛使用,但在其他编译器阶段,如语法分析和语义分析,可能会使用其他类型的自动机或文法来处理更复杂的语言结构。
词法分析生成的词法单元(Tokens)通常会在编译过程中被插入到符号表(Symbol Table)中。符号表是编译器中的一个重要数据结构,用于管理源代码中的标识符(变量名、函数名等)以及与之相关的信息。
当词法分析器识别出一个标识符时,它会将这个标识符作为一个词法单元生成,并将它的信息(如名称、类型、作用域等)添加到符号表中。符号表还可能包含其他类型的信息,如常量的值、函数的参数列表等。
在编译过程的后续阶段,比如语法分析和语义分析,编译器可以通过符号表来进行标识符的查找和类型检查。这对于正确解析和分析源代码的结构和含义至关重要。
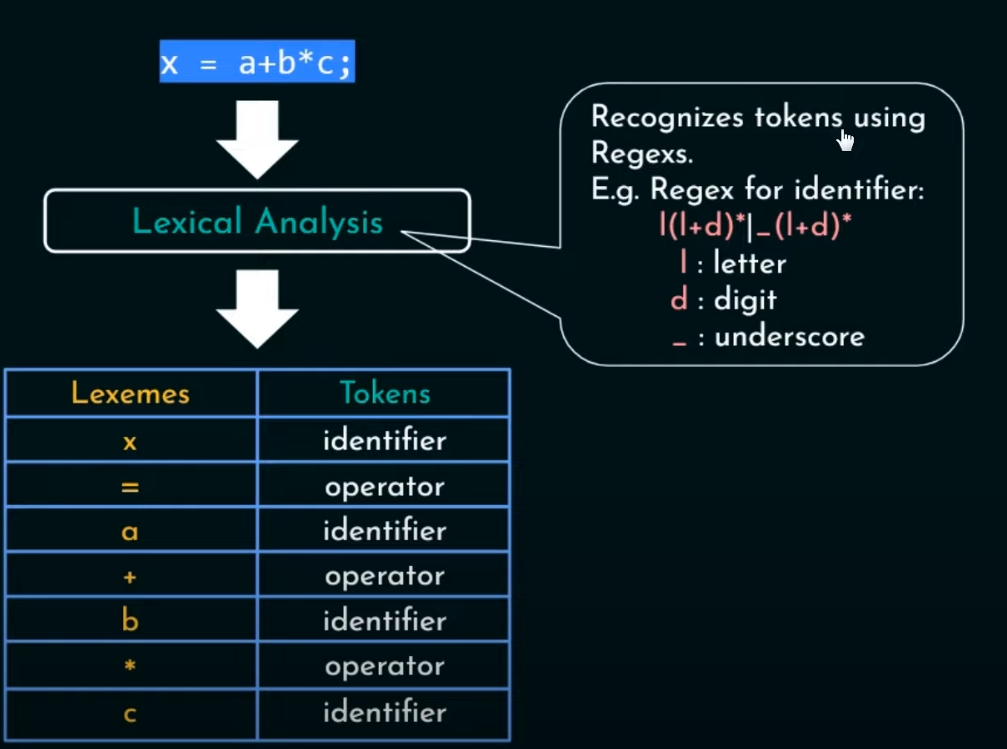
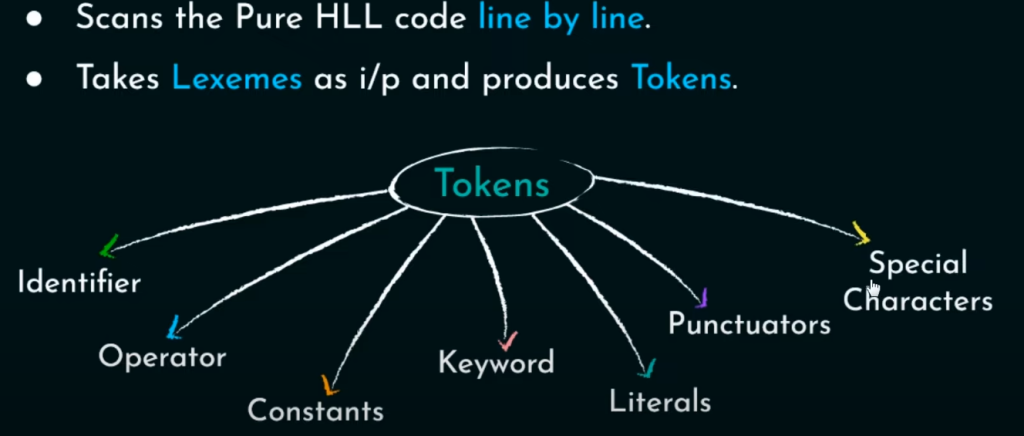
token主要有七种类型,分别是标识符,运算符,常量,关键字,字符串,标点符号,特殊符号。
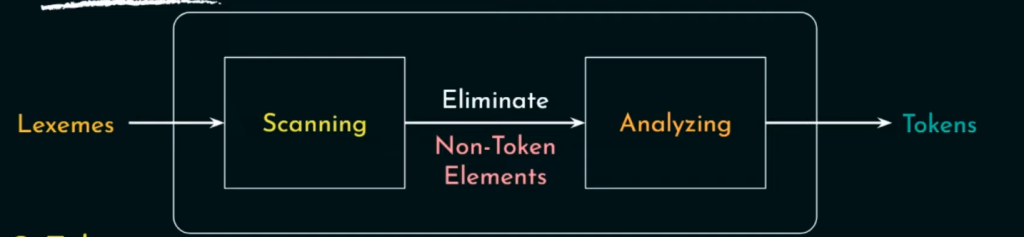
在扫描阶段会消除注释和非token元素,如空格和连续的空格等。
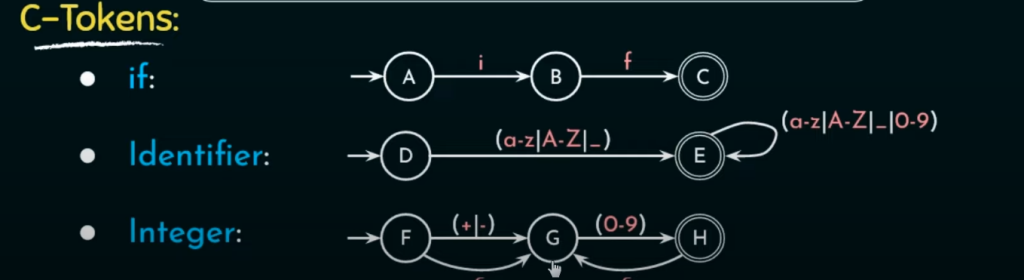
例如C语言的一些token可以通过正则表达式来匹配。
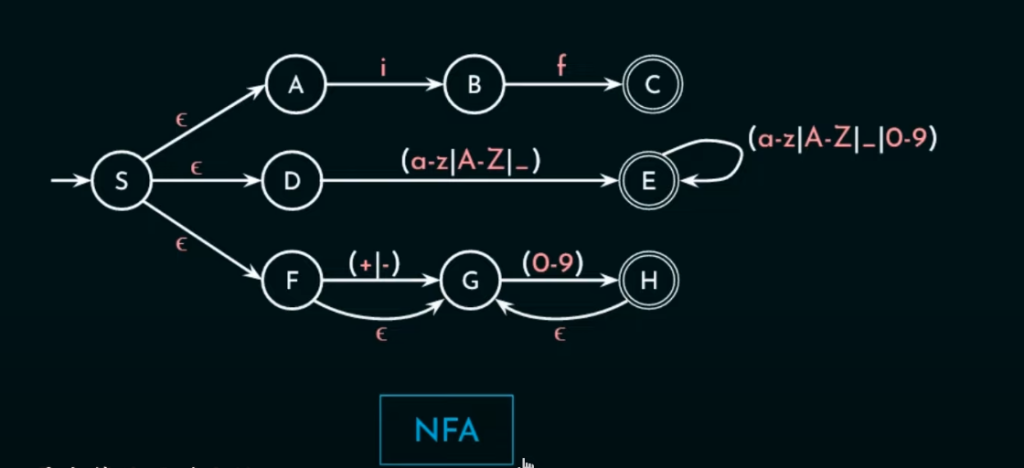
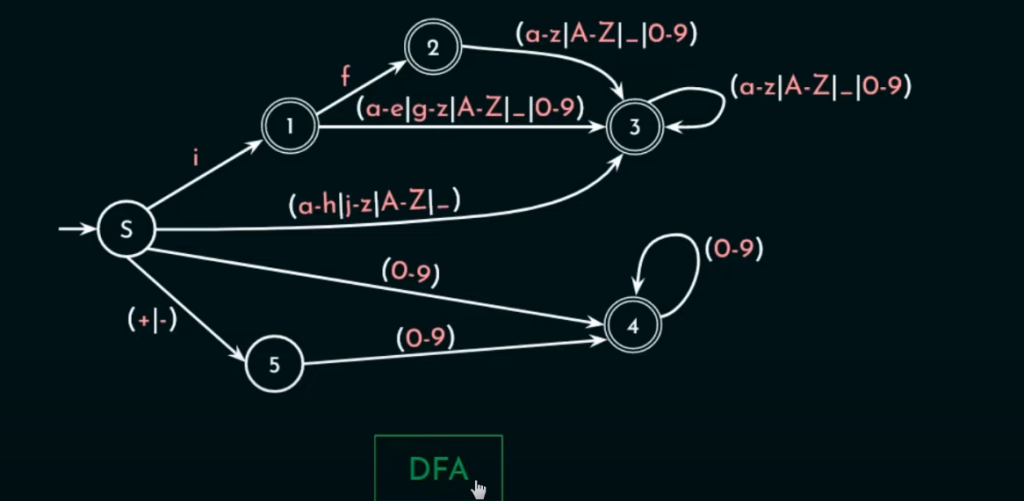
NFA变化太多较难以实现,实际上实现了等效的DFA来匹配。
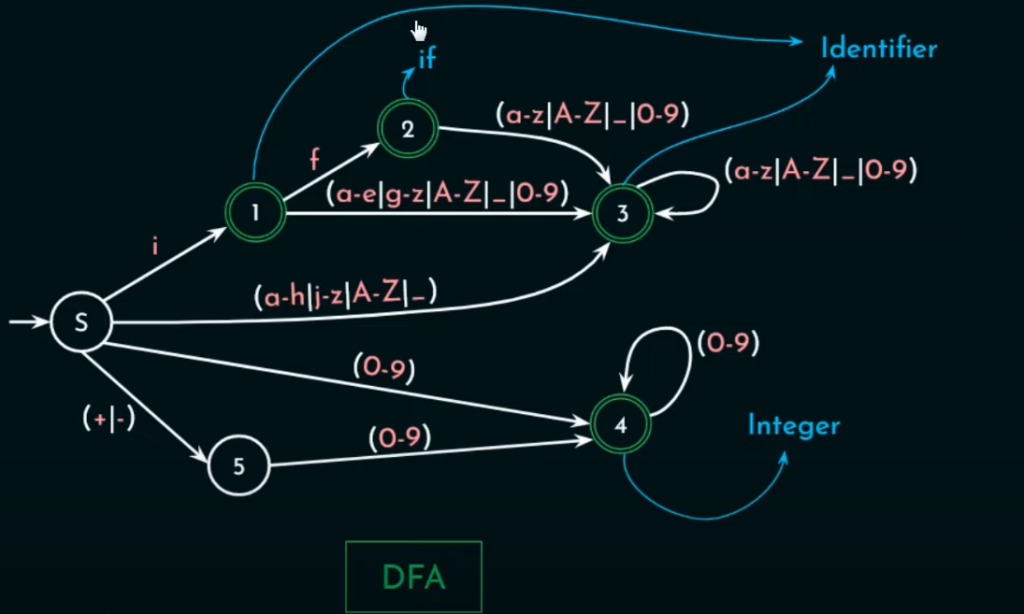
这个DFA模型可以识别标识符和关键字if和整数。

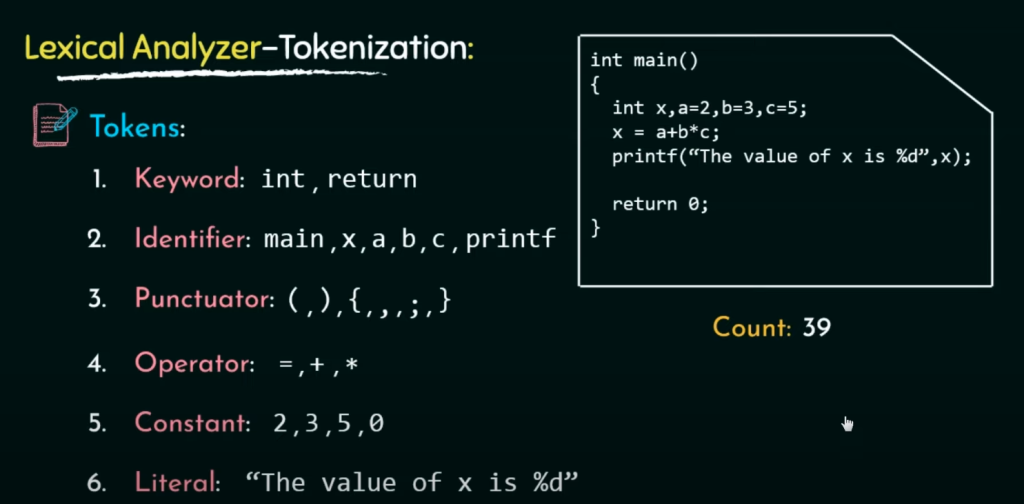
上述代码经过词法分析生成了39个不同类型的token!!!
Comments NOTHING