
看动画,彻底理解数据结构中图的知识,图的邻接表和邻接矩阵_哔哩哔哩_bilibili
dataStruct.md · blackdusts/ldc-study-notebook - Gitee.com
介绍、
图是一种非线性的数据结构,表示多对多的关系。图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V, E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
在图中需要注意的是:
线性表和树可以看做特殊的图。
线性表中我们把数据元素叫元素,树中将数据元素叫结点,在图中数据元素,我们则称之为顶点(Vertex)
线性表可以没有元素,称为空表;树中可以没有节点,称为空树;但是,在图中不允许没有顶点(有穷非空性)
线性表中的各元素是线性关系,树中的各元素是层次关系,而图中各顶点的关系是用边来表示(边集可以为空)。
图的分类、
1、无向图
顾名思义,无向图就是图上的边没有方向。
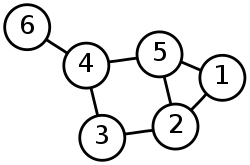
上图就是一个无向图。该图的顶点集为 V = { 1 , 2 , 3 , 4 , 5 , 6 } ,边集 E = { ( 1 , 2 ) , ( 1 , 5 ) , ( 2 , 3 ) , ( 2 , 5 ) , ( 3 , 4 ) , ( 4 , 5 ) , ( 4 , 6 ) }。在无向图中,边 ( u , v )和边 ( v , u )是一样的,也就是说和方向无关。
2、无向完全图、
在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。有n个顶点的无向完全图有n(n-1)/2 条边。
3、连通图(无向图)
在无向图G中,如果从顶点u到顶点v有路径,则称u和v是连通的。
如果对于图中任意两个顶点u、v,都有(u, v)∈E(即u和v都是连通的),则称G是连通图。
无向图中的极大连通子图称为连通分量。
连通分量需要满足:
必须是子图;
必须是连通的;
含有极大顶点数;
包含依附于这些顶点的所有边。
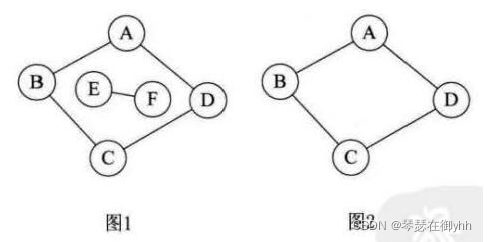
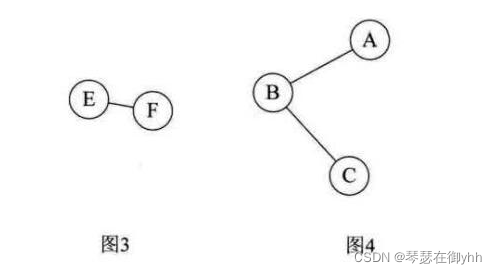
上图中,图1是无向非连通图(因为A与E不连通,即不满足图上任意两个顶点连通),但是有两个连通分量,即图2和图3。而图4,尽管是图1的子图,但是它却不满足连通子图的极大顶点数(图2满足)。 因此它不是图1的无向图的连通分量。
4、有向图
顾名思义,有向图就是图上的边有方向。
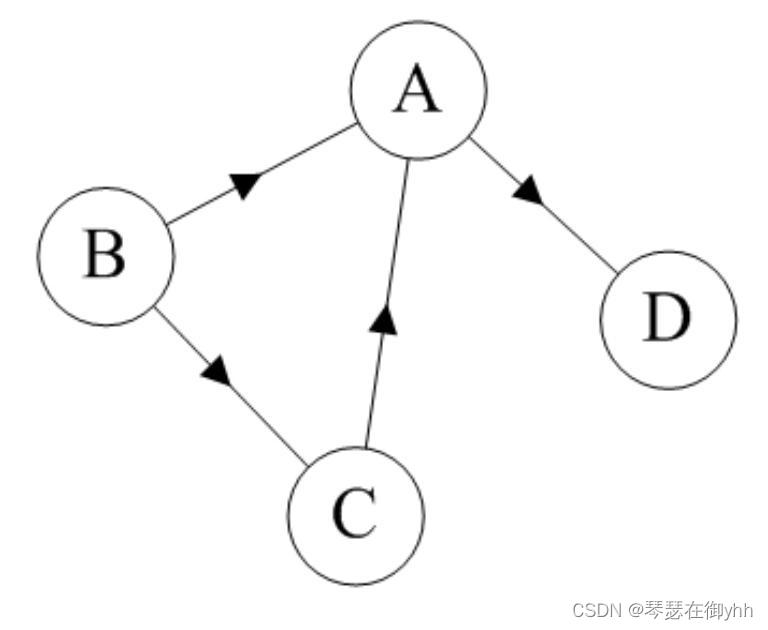
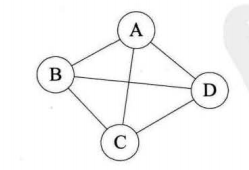
上图就是一个有向图。该图的顶点集为 V = { A , B , C , D } ,边集 E = { < B , A > , < B , C > , < C , A > , < A , D > }。在有向图中,边 < u , v >和边 < v , u >是不一样的。
通常情况下,有向图中的边用< >表示,无向图中的边用( )表示。
5、有向完全图
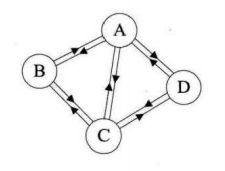
在有向图中,如果任意两个顶点之间都存在方向互为相反的两条边,则称该图为有向完全图。n个顶点的有向完全图含有n*(n-1)条边。
6、加权图和无权图
首先需要了解一下什么是权。有些图的边上具有与它相关的数字,这种与图的边相关的数叫做权(Weight)。这些权可以表示从一个顶点到另一个顶点的距离或耗费。因此加权图就是边上带有权重的图,与其对应的是无权图,或叫等权图,即边上没有权重信息。如果一张图不含权重信息,我们就认为边与边之间没有差别。
7、强连通图(有向图)
在有向图G中,如果对于每一对顶点vi、vj且vi≠vj,从vi到vj和从vj到vi都存在路径,则称G是强连通图。
有向图中的极大强连通子图称做有向图的强连通分量。
强连通图具有如下定理:一个有向图G是强连通的,当且仅当G中有一个回路,它至少包含每个节点一次。
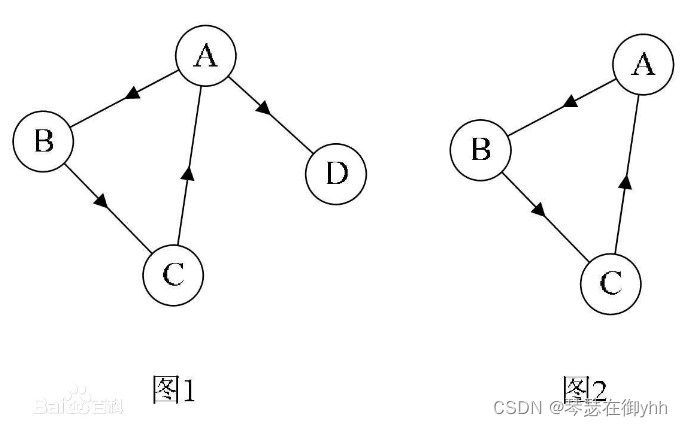
如上图所示,图1不是强连通图,因为对应C和D顶点来说它两不联通。图2是强连通图。图2也可以看做是图1的强连通分量。
一些概念、
1、有向图的度
对于有向图G = (V, E),如果边属于E,则称顶点v邻接到顶点v’,顶点v’邻接自顶点v的边和顶点v, v’相关联。
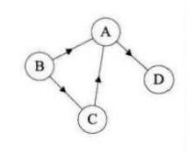
从顶点v出发的边的数目称为v的出度;到达顶点v的边的数目称为v的入度,顶点v的度=出度+入度。以下面这个有向图为例,
顶点A的入度是2 (从B到A的边,从C到A的边),出度是1(从A到D的边),所以顶点A的度为2+1=3。此有向图的边有4 条,而各顶点的出度和为1+2+1+0=4,各顶点的入度和=2+0+1+1=4。
2、稀疏图和稠密图
按照边的多少来分稀疏图和稠密图。假设一个图的顶点数为n,如果边数大于n*log n,则该图为稠密图,反之则为稀疏图。
图的存储结构、
1、邻接矩阵法
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点的信息,一个二维数组(称为邻接矩阵)存储图中边的信息。
(1)下图是使用邻接矩阵存储无向图。如图所示,设置两个数组,顶点数组为vertex[4] = {v0, v1, v2, v3},边数组arc[4][4]实际上是一个矩阵。对于矩阵的主对角线的值,即arc[0][0]、arc[1][1]、arc[2][2]、arc[3][3]全为0,这是因为顶点上不存在自环的边。通过这个例子可以看出,无向图的邻接矩阵是一个对称矩阵。
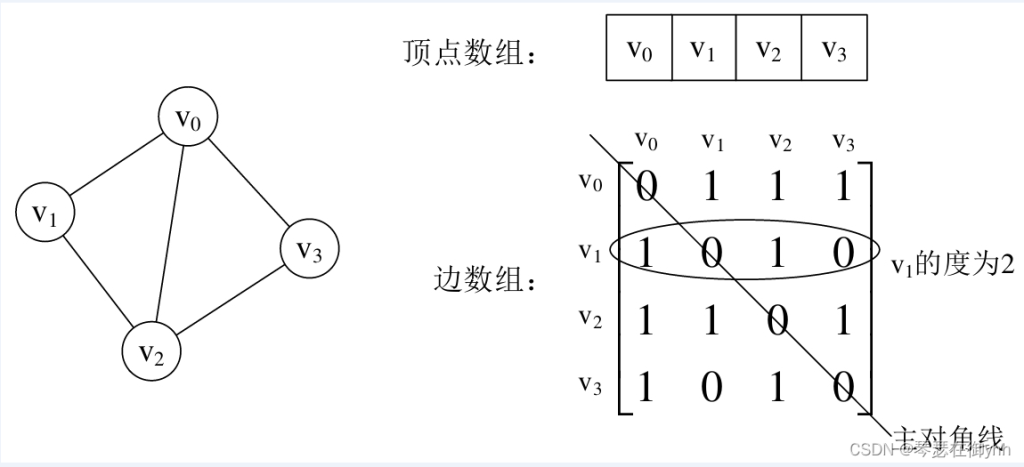
int vertex[4] = { 1,2,3,4 };
int arc[4][4] = { {0,1,1,1},{1,0,1,0 },{1,1,0,1},{1,0,1,0},};(2)下图是使用邻接矩阵存储有向图。如图所示,设置两个数组,顶点数组为vertex[4] = {v0, v1, v2, v3},边数组arc[4][4]实际上是一个矩阵。对于矩阵的主对角线的值,即arc[0][0]、arc[1][1]、arc[2][2]、arc[3][3]全为0,这是因为顶点上不存在自环的边。通过这个例子可以看出,有向图的邻接矩阵并不是一个对称矩阵。
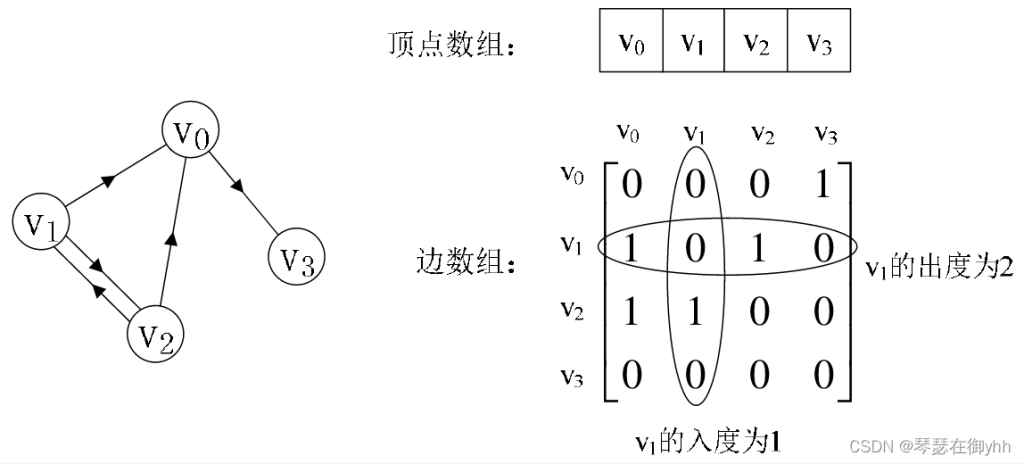
int vertex[4] = { 1,2,3,4 };
int arc[4][4] = { {0,0,0,1},{1,0,1,0 },{1,1,0,0},{0,0,0,0},};邻接矩阵图的数据结构实现和遍历如下
#include<iostream>
#define _CRTDBG_MAP_ALLOC
using namespace std;
#include<crtdbg.h>
#include<cassert>
#include<queue>
void optimizeIOstreamAndCheckLeakMemory()
{
_CrtSetDbgFlag(33);
ios::sync_with_stdio(false);
cin.tie(0);
}
const size_t vertexNumbers = 4;
class Vertex
{
public:
Vertex(int data = 0):data(data){}
~Vertex()noexcept{}
int data;
};
class Graph
{
public:
Graph()
{
for (size_t i = 0; i < vertexNumbers; ++i)
{
vertexs[i] = 0;
isVisitedArray[i] = 0;
}
for (size_t i = 0; i < vertexNumbers; ++i)
{
for (size_t j = 0; j < vertexNumbers; ++j)
{
edges[i][j] = 0;
}
}
}
~Graph()noexcept{
try
{
for (size_t i = 0; i < vertexNumbers; ++i)
{
if (vertexs[i])
{
delete vertexs[i];
}
}
}
catch (...)
{
}
}
Vertex* vertexs[vertexNumbers];
int edges[vertexNumbers][vertexNumbers];
bool isVisitedArray[vertexNumbers];
void clearIsVisitedArray()
{
for (size_t j = 0; j < vertexNumbers; ++j)
{
isVisitedArray[j] = 0;
}
}
void BFS(size_t pos)
{
assert(pos >= 0 && pos < vertexNumbers);
clearIsVisitedArray();
visit(pos);
isVisitedArray[pos] = 1;
queue<size_t> q;
q.push(pos);
while (!q.empty())
{
size_t cur = q.front();
q.pop();
for (size_t j = 0; j < vertexNumbers; ++j)
{
if (edges[cur][j] == 1 && isVisitedArray[j] == 0)
{
visit(j);
isVisitedArray[j] = 1;
q.push(j);
}
}
}
clearIsVisitedArray();
}
void DFS(size_t pos)
{
assert(pos >= 0 && pos < vertexNumbers);
visit(pos);
isVisitedArray[pos] = 1;
for (size_t i = 0; i < vertexNumbers; ++i)
{
if (edges[pos][i] == 1 && isVisitedArray[i] == 0)
{
DFS(i);
}
}
}
void visit(size_t pos)
{
assert(pos >= 0 && pos < vertexNumbers);
cout << vertexs[pos]->data << endl;
}
};
int main()
{
optimizeIOstreamAndCheckLeakMemory();
Graph graph;
for (size_t i = 0; i < vertexNumbers; ++i)
{
graph.vertexs[i] = new Vertex(i*2);
}
graph.edges[0][1] = 1;
graph.edges[0][2] = 1;
graph.edges[0][3] = 1;
graph.edges[1][0] = 1;
graph.edges[1][2] = 1;
graph.edges[2][1] = 1;
graph.edges[2][0] = 1;
graph.edges[2][3] = 1;
graph.edges[3][0] = 1;
graph.edges[3][2] = 1;
graph.BFS(2);
graph.DFS(1);
return 0;
}
2、邻接表法
邻接表由表头节点和表节点两部分组成,图中每个顶点均对应一个存储在数组中的表头节点。如果这个表头节点所对应的顶点存在邻接节点,则把邻接节点依次存放于表头节点所指向的单向链表中。
(1)下图所示的就是一个无向图的邻接表结构。从该图可以看出,顶点表的各个结点由data和firstedge两个域表示,data是数据域,存储顶点的信息,firstedge是指针域,指向边表的第一个结点,即此顶点的第一个邻接点。边表结点由adjvex和next两个域组成。adjvex是邻接点域,存储某顶点的邻接点在顶点表中的下标,next则存储指向边表中下一个结点的指针。例如:v1顶点与v0、v2互为邻接点,则在v1的边表中,adjvex分别为v0的0和v2的2。
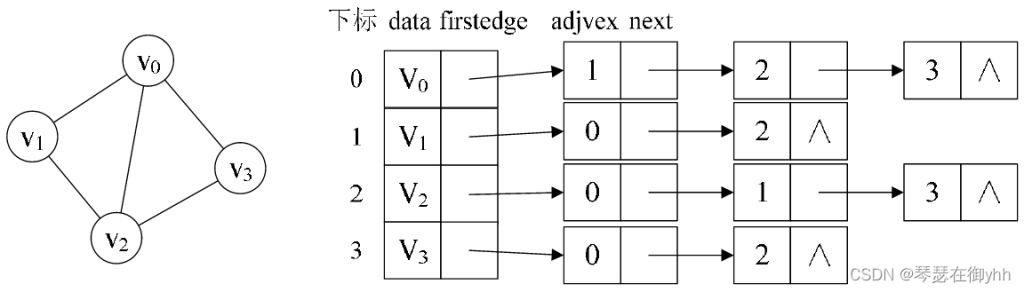
(2)下图是使用邻接表存储有向图。值得注意的是,由于有方向的,因此有向图的邻接表分为出边表和入边表(又称逆邻接表),出边表的表节点存放的是从表头节点出发的有向边所指的尾节点;入边表的表节点存放的则是指向表头节点的某个顶点。
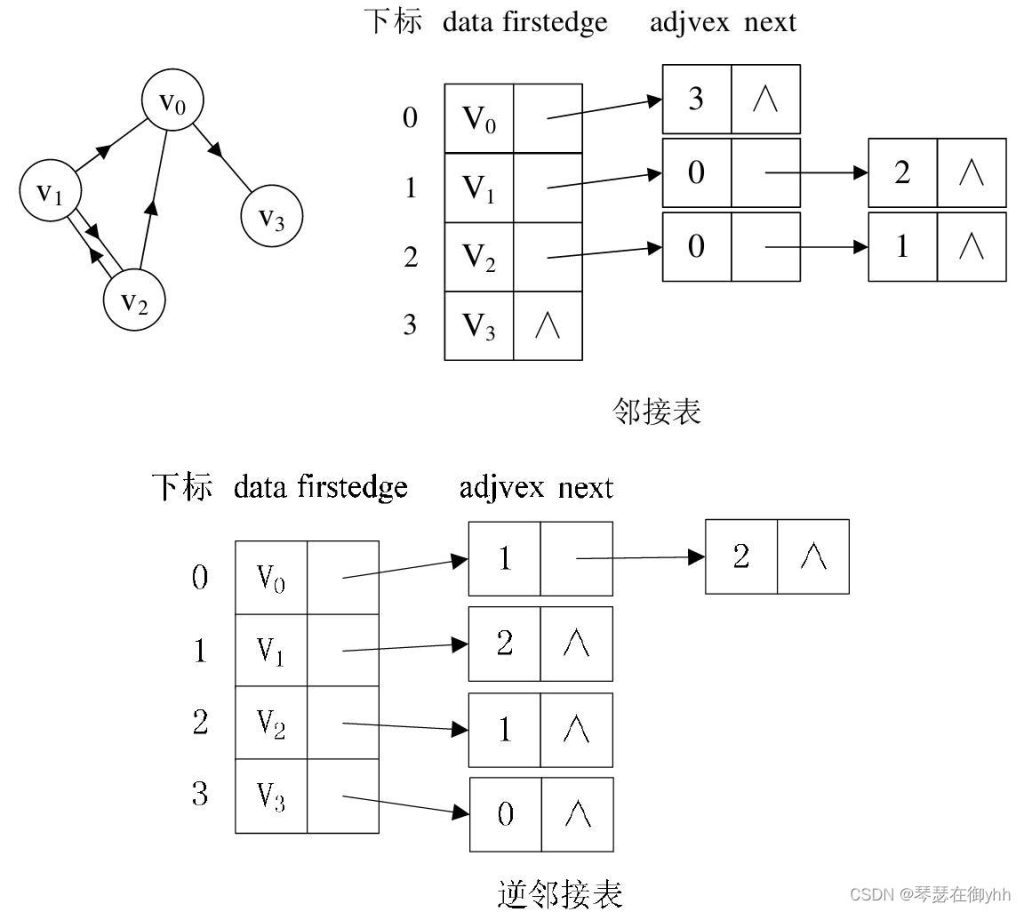
显而易见,如果图是一个稀疏图,用邻接表进行存储比较合适,如果图是一个稠密图,则用邻接矩阵更合适。
图的遍历、
图的遍历:就是依次访问所有的结点,且不能重复访问某个结点,且要避免死循环,所以应该把访问过的结点加上标记。
DFS、
深度优先搜索法(DFS)是树的先根遍历的推广,它的基本思想是:从图G的某个顶点v0出发,访问v0,然后选择一个与v0相邻且没被访问过的顶点vi访问,再从vi出发选择一个与vi相邻且未被访问的顶点vj进行访问,依次继续。如果当前被访问过的顶点的所有邻接顶点都已被访问,则退回到已被访问的顶点序列中最后一个拥有未被访问的相邻顶点的顶点w,从w出发按同样的方法向前遍历,直到图中所有顶点都被访问。
BFS、
图的广度优先搜索是树的按层次遍历的推广,它的基本思想是:首先访问初始点vi,并将其标记为已访问过,接着访问vi的所有未被访问过的邻接点vi1,vi2,…, vi t,并均标记已访问过,然后再按照vi1,vi2,…, vi t的次序,访问每一个顶点的所有未被访问过的邻接点,并均标记为已访问过,依次类推,直到图中所有和初始点vi有路径相通的顶点都被访问过为止。
邻接表图的实现和遍历的代码如下
#include<iostream>
#define _CRTDBG_MAP_ALLOC
using namespace std;
#include<crtdbg.h>
#include<cassert>
#include<queue>
#include<stack>
void optimizeIOstreamAndCheckLeakMemory()
{
_CrtSetDbgFlag(33);
ios::sync_with_stdio(false);
cin.tie(0);
}
class Arc;
const size_t vertexNumbers = 5;
//顶点结构体信息
class Vertex
{
public:
Vertex():firstEdge(0),data(0){}
~Vertex()noexcept{}
Arc* firstEdge = 0; //指向边表结点的指针
int data = 0; //数据域
};
//边表结点结构体信息
class Arc
{
public:
Arc(int adj = 0,Arc*nex = 0):next(nex),adjvex(adj){}
~Arc()noexcept{}
Arc* next = 0; //指向下一个边表结点的指针
size_t adjvex = 0 ; //邻接点的编号
};
class Graph
{
public:
Graph()
{
for (size_t i = 0; i < vertexNumbers; ++i)
{
vertexs[i] = 0;
isVisited[i] = 0;
}
for (size_t i = 0; i < vertexNumbers; ++i)
{
for (size_t j = 0; j < vertexNumbers; ++j)
{
edges[i][j] = 0;
}
}
}
~Graph()noexcept
{
try
{
for (size_t i = 0; i < vertexNumbers; ++i)
{
if (vertexs[i])
{
delete vertexs[i];
}
}
for (size_t i = 0; i < vertexNumbers; ++i)
{
for (size_t j = 0; j < vertexNumbers; ++j)
{
if (edges[i][j])
{
delete edges[i][j];
}
}
}
}
catch (...)
{
}
}
Vertex* vertexs[vertexNumbers]; //顶点数组
Arc* edges[vertexNumbers][vertexNumbers]; //边表结点数组
bool isVisited[vertexNumbers]; //访问标志数组
//清除访问标记数组
void clearIsVisited()
{
for (size_t i = 0; i < vertexNumbers; ++i)
{
isVisited[i] = 0;
}
}
//广度优先遍历BFS
void BFS(size_t start)
{
assert(start >= 0 && start < vertexNumbers);
clearIsVisited();
visit(start); //先访问入口的顶点
isVisited[start] = 1; //标记为已经访问过
queue<size_t> q; //建立一个顶点编号队列
q.push(start); //入队列
while (!q.empty())
{
size_t cur = q.front(); //出队列
q.pop();
//依次访问入口顶点的所有邻接点
for (size_t i = 0; i < vertexNumbers; ++i)
{
if (edges[cur][i] != 0 && isVisited[i] == 0)
{
visit(i);
isVisited[i] = 1; //标记为已经访问过
q.push(i); //访问过的顶点入队列
}
}
}
clearIsVisited();
}
//深度优先遍历DFS
void DFS(size_t start)
{
assert(start >= 0 && start < vertexNumbers);
visit(start);
isVisited[start] = 1;
//查找start顶点的未被访问的邻接点
for (size_t i = 0; i < vertexNumbers; ++i)
{
if (edges[start][i] != 0 && isVisited[i] == 0)
{
DFS(i);
}
}
}
void visit(size_t pos)
{
assert(pos < vertexNumbers && pos >=0);
cout << vertexs[pos]->data << endl;
}
};
int main()
{
optimizeIOstreamAndCheckLeakMemory();
Graph graph;
for (size_t i = 0; i < vertexNumbers; ++i)
{
graph.vertexs[i] = new Vertex();
}
for (size_t i = 0; i < vertexNumbers; ++i)
{
graph.vertexs[i]->data = i*2;
}
graph.edges[0][0] = 0; // 没有顶点1到顶点1的边
graph.edges[0][3] = new Arc(3,0); //第三条边
graph.edges[0][2] = new Arc(2, graph.edges[0][3]); //第二条边
graph.edges[0][1] = new Arc(1, graph.edges[0][2]); //第一条边
graph.vertexs[0]->firstEdge = graph.edges[0][1]; //顶点1指向第一条边
graph.edges[1][1] = 0; // 没有顶点2到顶点2的边
graph.edges[1][0] = new Arc(0, 0); //第二条边
graph.edges[1][2] = new Arc(2, graph.edges[1][0]); //第一条边
graph.vertexs[1]->firstEdge = graph.edges[1][2]; //顶点2指向第一条边
graph.edges[2][2] = 0; // 没有顶点3到顶点3的边
graph.edges[2][4] = new Arc(4, 0); //第四条边
graph.edges[2][0] = new Arc(0, graph.edges[2][4]); //第三条边
graph.edges[2][1] = new Arc(1, graph.edges[2][0]); //第二条边
graph.edges[2][3] = new Arc(3, graph.edges[2][1]); //第一条边
graph.vertexs[2]->firstEdge = graph.edges[2][3]; //顶点3指向第一条边
graph.edges[3][3] = 0; // 没有顶点4到顶点4的边
graph.edges[3][0] = new Arc(0, 0); //第二条边
graph.edges[3][2] = new Arc(2, graph.edges[3][0]); //第一条边
graph.vertexs[3]->firstEdge = graph.edges[3][2]; //顶点4指向第一条边
graph.edges[4][4] = 0;
graph.edges[4][2] = new Arc(2, 0);
graph.vertexs[4]->firstEdge = graph.edges[4][2];
graph.BFS(4);
graph.DFS(0);
return 0;
}
Comments NOTHING