

编译器的功能是将高级语言代码翻译成机器代码。过程有四个阶段,预处理阶段,编译阶段,汇编阶段,链接/加载阶段。

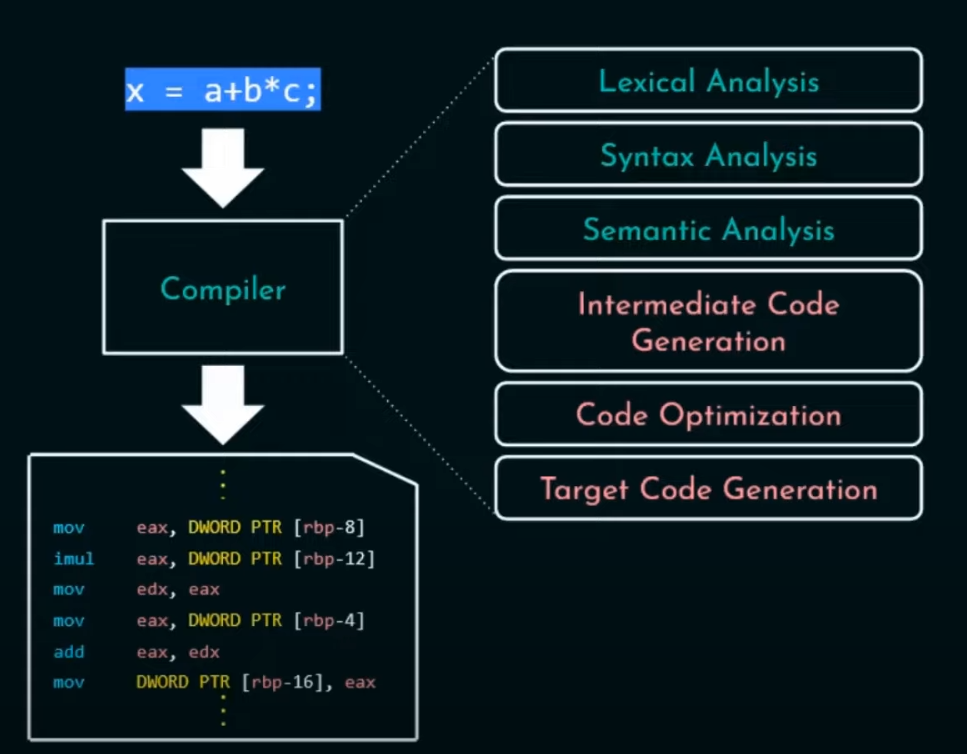
编译器架构有六个阶段,从上到下分别是词法分析,语法分析,语义分析,中间代码生成,代码优化,机器代码生成。

前四个阶段较为重要,可以称为前端,后面称为后端。
词法分析、
是编译原理中的一个重要步骤,用于将源代码中的字符序列(通常是文本)转化为一个个的词法单元(Tokens)。每个词法单元代表着语言中的一个基本单位,例如关键字、标识符、运算符、常量等。
主要作用如下:
- 分割字符序列: 词法分析将源代码按照语法规则分割成一系列词法单元,这些词法单元是语言中的基本构建块,便于后续的语法分析和语义分析。
- 去除空白和注释: 在词法分析阶段,可以将源代码中的空格、制表符、换行等空白字符去除,以及注释部分被忽略,这样可以减小后续分析的复杂性。
- 词法单元分类: 词法分析器根据预定义的词法规则,将字符序列划分为不同的词法单元类型,如关键字、标识符、运算符、分隔符、常量等。
- 构建符号表: 词法分析阶段还可以根据标识符的出现情况构建符号表,用于记录各个标识符的属性和信息,为后续的语义分析和代码生成提供支持。
- 错误检测: 在词法分析过程中,可以检测并报告一些简单的词法错误,例如非法字符、未知的词法单元等。

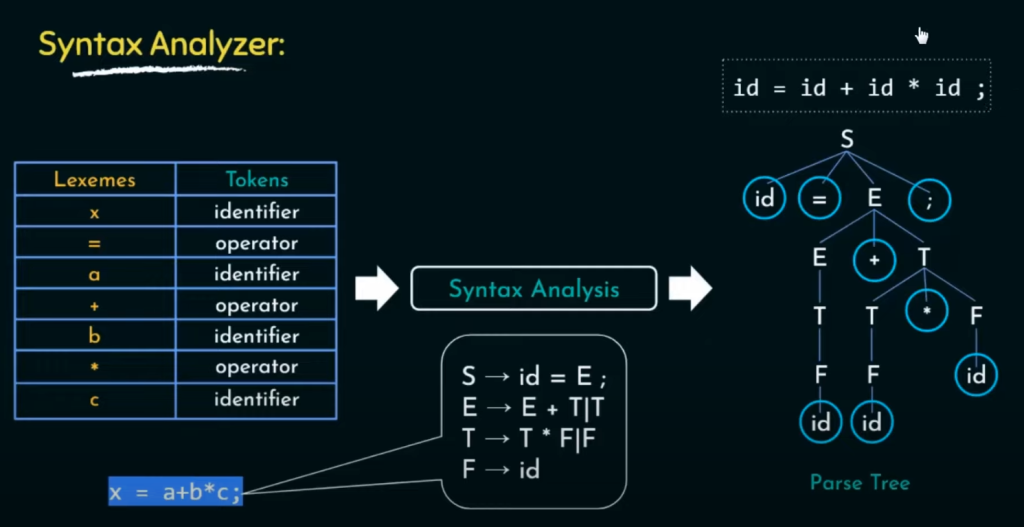
例如 x = a + b * c 的语句经过词法分析后生成如上的词法表;词法分析识别标识符使用正则表达式来识别,标识符也就是俗称的变量名称,函数名称等等不能以数字开头但是可以以字母或者下划线开头!!!
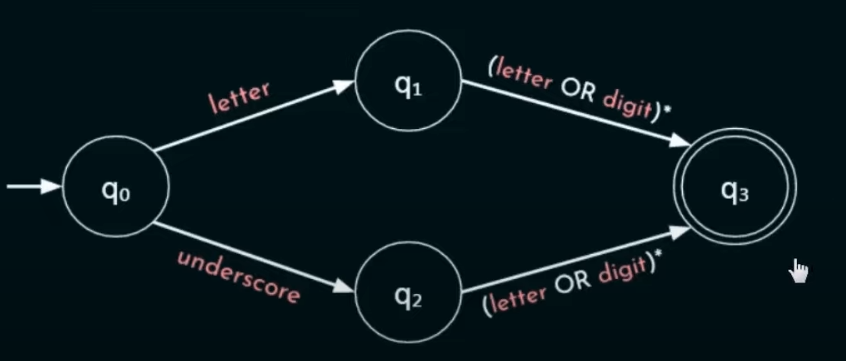
上述图就是识别过程,只接受字母或者下划线开头的标识符,不然就报错!!!
语法分析、
将程序代码(通常是源代码)解析为抽象语法树(AST)或类似的数据结构,以便进一步的编译、解释或分析。语法分析器负责检查代码是否遵循特定编程语言的语法规则,并将其转化为可供后续阶段处理的数据表示形式。
主要作用如下:
- 语法正确性检查: 语法分析器能够识别和报告代码中的语法错误。它会检查代码是否符合编程语言的语法规则,如括号的匹配、关键字的使用、语句结束符的正确放置等。通过这种检查,可以避免在后续的阶段中处理具有明显语法问题的代码,从而提高了编程的准确性和效率。
- 代码结构建模: 语法分析器将源代码转换为抽象语法树(AST)或类似的数据结构。AST表示了代码的层次结构和逻辑关系,使得编译器或解释器能够更轻松地理解和处理代码。这种抽象表示有助于后续阶段的代码优化、分析和生成。
- 语义分析的基础: 虽然语法分析本身不涉及代码的含义,但它为后续的语义分析提供了基础。语法分析器在构建抽象语法树的过程中,可以收集一些关于标识符、数据类型等方面的信息,为语义分析阶段提供必要的上下文。
- 中间代码生成: 一些编译器在语法分析阶段还可以生成中间代码(Intermediate Representation,IR)。中间代码是一种介于源代码和目标代码之间的抽象表示,它可以进一步被优化和转化为目标代码,以便最终的执行或生成。
- 错误报告和提示: 语法分析器能够定位和识别代码中的语法错误,并提供有关错误类型和位置的信息。这些错误报告可以帮助开发人员快速定位问题并进行修复,从而提高了代码质量和开发效率。
语义分析、
语法分析器负责检查代码是否符合语法规则,而语义分析则关注代码的含义和语义合理性。语义分析的主要目标是解释代码的意图,对代码中的语义错误进行检测,并为后续的优化和代码生成阶段提供必要的信息。
语义分析的作用和任务包括:
- 类型检查: 语义分析器会检查代码中的数据类型是否匹配,例如检查赋值语句左右两边的数据类型是否兼容,函数调用时实际参数和形式参数的类型是否匹配等。类型检查有助于避免在运行时发生类型错误,提前发现潜在的问题。
- 作用域和标识符管理: 语义分析器负责管理标识符(变量、函数名等)的作用域和生命周期。它会确保在代码中正确地使用变量,检查变量是否在正确的作用域内声明和使用,避免命名冲突等问题。
- 常量折叠: 在语义分析阶段,可以对表达式中的常量进行折叠计算,以减少后续阶段的工作量和优化机会。例如,将
2 + 3这样的表达式折叠为一个常量5。 - 语义错误检测: 语义分析器会检测代码中的一些语义错误,例如未定义的变量使用、函数参数个数不匹配、不兼容的类型转换等。这些错误可能不会在语法分析阶段被捕获,但会在语义分析阶段被发现。
- 类型推导: 在一些编程语言中,变量的类型可以由编译器推导出来,而不需要显式声明。语义分析器可能会参与类型推导的过程,从代码的上下文中推断变量的类型。
- 生成中间代码: 语义分析阶段有时也涉及生成中间代码,以便后续的优化和代码生成。中间代码是对原始代码的一种抽象表示,可以在不同平台上进行优化和转换。

中间代码生成、
中间代码生成是编译器的一个重要阶段,位于语义分析之后,优化之前。在这个阶段,编译器将高级语言源代码转换为一种抽象的、中间层次的代码表示,这种表示介于源代码和目标代码之间,通常更加易于进行优化和后续处理。中间代码生成的主要目标是将源代码的语义保留下来,同时为优化阶段提供方便。
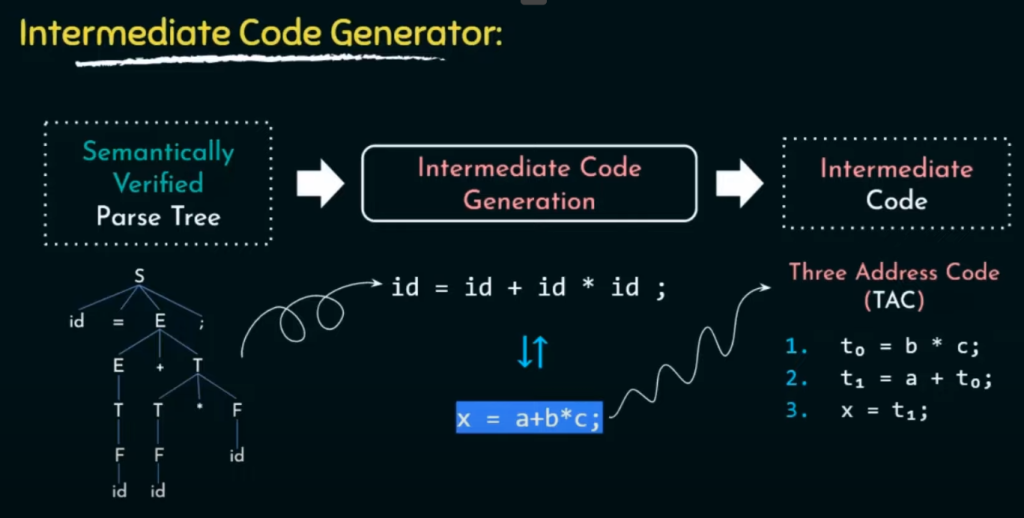
三地址码(Three-Address Code): 这是一种将表达式和指令都表示为最多三个操作数的形式,例如 x = y + z 可以表示为 t = y + z 和 x = t,如上图所示。
代码优化、
主要目标是通过改进代码的性能、执行效率、资源利用等方面来提高程序的质量和效率,而不改变程序的语义。

上述图中三行代码有多余的一行,直接就优化掉了。
代码优化可以分为多种类型,包括但不限于:
- 局部优化: 针对单个基本块或基本块之间的操作进行的优化。常见的局部优化包括常量传播、公共子表达式消除、死代码消除等。
- 全局优化: 考虑整个程序的优化。全局优化可以进行诸如循环优化、循环不变式外提、代码移动等操作,以提高程序整体的效率。
- 数据流分析: 这是一种用于分析程序中数据流的技术,包括活跃变量分析、可达定义分析等。数据流分析的结果可以用来指导优化决策,如寻找可以被消除的死代码。
- 内存优化: 优化内存访问模式,包括缓存友好的数据排列、减少内存分配和释放操作等。
- 指令级优化: 针对特定的目标机器指令集,进行指令选择、寄存器分配等操作,以提高生成的机器代码的效率。
- 并行和向量化优化: 利用多核处理器和SIMD(Single Instruction, Multiple Data)指令,将循环或操作并行化或向量化,以提高并行执行效率。
- 函数内联: 将函数调用替换为函数体内的代码,减少函数调用开销。
- 代码重排: 优化指令的顺序,以最大程度地减少流水线中的冒险和延迟。
- 循环优化: 重写、展开、拆分和向量化循环,以提高循环的执行效率。
目标代码生成、
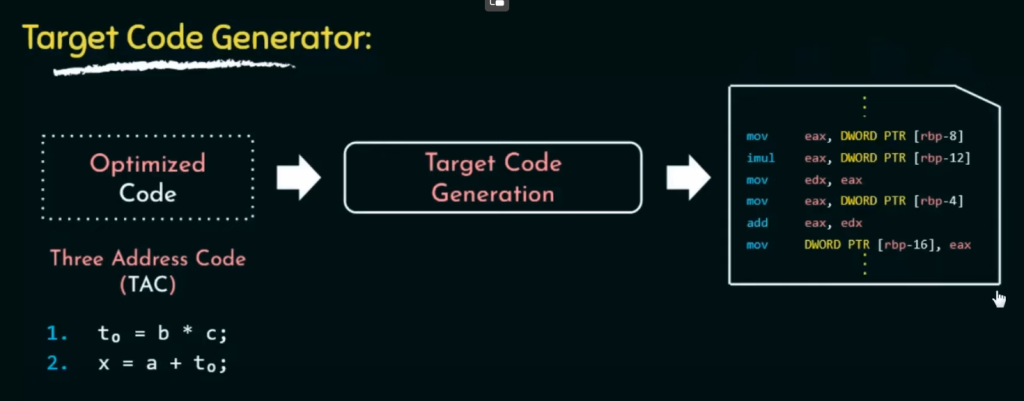
目标代码生成是编译器的最后一个主要阶段,目标代码生成阶段会产生汇编代码,而不是直接生成可执行的二进制机器代码。汇编代码是类似于人类可读的文本形式的表示,其中包含了特定汇编语言的指令、操作数和标号。然后,汇编代码需要通过汇编器进行处理,将其转换为计算机能够直接执行的机器代码,这个机器代码是由二进制指令构成的,可以被计算机硬件解释和执行。
Comments NOTHING