
前言、
现代计算机存储和处理的信息以二值信号表示。这些微不足道的二进制数字,或者称为 位(bit),形成了数字革命的基础。大家熟悉了 1000 多年前的十进制(以 10 为基础)起源于印度,在 12 世纪被阿拉伯数学家改进,并在 13 世纪被意大利科学家 Leonardo Pisano(大约公元 1170 - 1250,更为大家熟知的名字是 Fibonacci)带到西方。对于有是个手指的人类来说,使用十进制表示法是很自然的事情,但是当构造存储和处理信息的机器时,二进制工作的更好。二值信号,能够更容易的被表示、存储和传输。例如,可以表示为穿孔卡片上有洞或无洞、导线上的高电压或低电压、或者顺时针或逆时针的磁场。对二值信号进行存储和执行计算的电子电路非常简单和可靠,制造商能够在一个单独的硅片上集成数百万甚至数亿个这样的电路。
孤立的讲,单个的位不是非常有用。然而,当把这些位组合在一起,再加上某种解释,即赋予不同的可能位模式以含意,我们就能够表示任何有限集合的元素。比如,使用一个二进制数字系统,我们能够用位组来编码非负数。通过使用标准的字符码,我们能够对文档中的字母和符号进行编码。在本章中,我们将讨论这两种编码,以及负数表示和实数近似值的编码。
计算机存储和处理的信息以二值信号表示。“位(bit)”形成了数据革命的基础
无符号(unsigned)编码基于传统的二进制表示法,表示大于或者等于零的数字。补码(two's-complement)编码是表示有符号整数的最常见的方式,有符号整数就是可以为正或者负的数字。
计算机的表示法是用有限数量的位来对一个数字编码,因此结果太大以致不能表示时,某些运算就会溢出。
浮点数运算有完全不同的数学属性。虽溢出会产生特殊的值+∞,但是一组正数的乘积总是正的,浮点数运算不能运用结合律
信息存储、
大多数计算机使用8位的块,或者字节(byte),作为最小的可寻址的内存单位,而不是访问内存中单独的位。机器级程序将内存视为一个非常大的字节数组,称为虚拟内存。内存的每一个字节都由一个唯一的数字来标识,称为它的地址,所有可能地址的集合就称为虚拟地址空间。
在接下来的几章中,我们将讲述编译器和运行时系统是如何将存储器空间划分为更可管理的单元,来存放不同的 程序对象 (project object),即 程序数据、指令和控制信息。可以用各种机制来分配和管理程序不同部分的存储。这种管理完全是在 虚拟地址空间 里完成的。例如,C 语言中一个指针的值(无论它指向一个整数、一个结构或某个其他程序对象)都是某个存储块的第一个字节的虚拟地址。C 编译器还把每个指针和类型信息联系起来,这样就可以根据指针值的类型,生成不同的机器级代码来访问存储在指针所指向位置处的值。尽管 C 编译器还维护着这个类型信息,但是它生成的实际机器级程序并不包含数据类型的信息。每个程序对象可以简单的视为一个字节块,而程序本身就是一个字节序列。
十六进制表示法、
一个字节由 8 位 组成。在二进制表示法中,它的值域是 0000 00002 ~ 1111 11112 。如果看成十进制整数,它的值域就是 010 ~ 25510。两种符号表示法对于描述 位模式 来说,都不是非常方便。二进制表示法太冗长,而十进制表示法与位模式的互相转化很麻烦。替代的方法是,以 16 位基数,或者叫做 十六进制数 (hexadecimal),来表示 位模式。十六进制(简写位为 'hex‘)使用数字 ‘0’ ~ ‘9’ 以及字符 ‘A’ ~ ‘F’ 来表示 16 个可能的值。下图展示了 16 个十六进制数字对应的十进制值和二进制值。用十六进制书写,一个字节的值域为 0016 ~ FF16。

在 C 语言中,以 0x 或 0X 开头的数字常量被认为是十六进制的值。字符 ‘A’ ~ ‘F’ 既可以是大写,也可是小写。例如,我们可以将数字 FA1D37B16 写作 0xFA1D37B,或者 0xfa1d37b,甚至是大小写混合,比如,0xFa1D37b。在本书中,我们将使用 C 表示法来表示十六进制值。
编写机器级程序 的一个 常见任务 就是 在位模式的十进制、二进制和十六进制表示之间人工转换。二进制和十六进制之间的转换比较简单直接,因为可以一次执行一个十六进制数字的转换。数字的转换可以参考如图所示的表。一个简单的窍门是,记住十六进制数字 A、C 和 F 相对应的十进制。而对于把十六进制 B、D、E转换成十进制,则可以通过计算它们与前三个值的相对关系来完成。
比如,假设给你一个数字 0x173A4C。可以通过展开每个十六进制数字,将它转换为二进制格式,如下所示:

这样就得到了二进制表示 000101110011101001001100。
反过来,如果给定一个二进制数字,可以通过首先把它分为每 4 个一组来转换成十六机制。不过要注意,如果位总数不是 4 的倍数,最左边的一组可以少于 4 位,前面用 0 补足。然后将每个 4 位组转换为对应的十六进制。

字数据大小、
每台计算机都有“字长”,指明指针数据的标称大小。虚拟地址是以这样的一个字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。对于一个字长为w的机器而言,虚拟地址的范围0~2^w-1,程序最多访问2W个字节,例如32位字长最大约为4GB,64位则很大很大,为16EB,约等于无限。 大多数 64 位机器也可以运行 32 位机器编译的程序,这是一种向后兼容,而32位机器不能够运行64位机器编译的程序。
C 语言支持整数和浮点数的多种数据格式。图 2-3 展示了为 C 语言各种数据类型分配的字节数。有些数据类型的确切字节数依赖于程序是如何被编译的。我们给出的是 32 位 和 64 位 程序的典型值。整数或者为有符号的,即 可以表示 负数、零 和 正数;或者为无符号的,即 只能表示 非负数。C 的数据类型 char 表示一个单独的字节。尽管 “char” 是由于它被用来存储文本串中的单个字符这一事实而得名,但它也能被用来存储整数值。数据类型 short、int 和 long 可以提供各种数据大小。即使是为 64 位系统编译,数据类型 int 通常也只有 4 个字节。数据类型 long 一般在 32 位程序中为 4 字节,在 64 位程序中则为 8 字节。
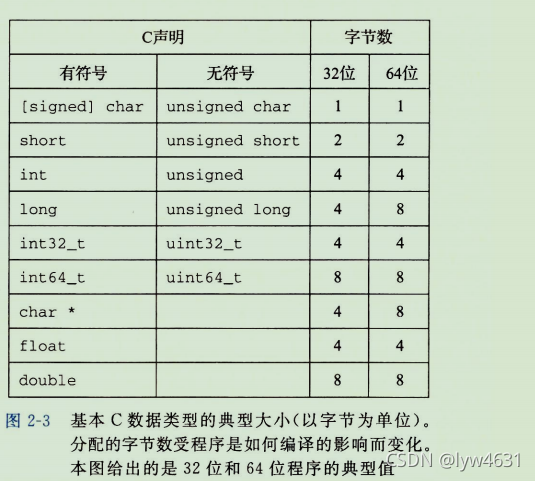
为了避免由于依赖 “典型” 大小和不同编译器设置带来的奇怪行为, ISO C99 引入了一类数据类型,其数据大小是固定的,不随编译器和机器设置而变化。其中就有数据类型 int32_t 和 int64_t,他们分别为 4 个字节和 8 个字节。使用确定大小的整数类型是程序员精准控制数据表示的最佳途径。
大部分数据类型都编码为 有符号数值,除非有前缀关键字 unsigned 或对确定大小的数据类型使用了特定的无符号声明。数据类型 char 是一个例外。尽管大多数编译器和机器将它们视作有符号数,但 C 标准不保证这一点。相反,正如方括号指示的那样,程序员应该用有符号字符的声明来保证其为一个字节的有符号数值。不过,在很多情况下,程序行为对数据类型 char 是有符号的还是无符号的并不敏感。
程序员应该尽力使 他们的程序在不同的机器和编译器上可移植。可移植性的一个方面就是 使程序对不同数据类型的确切大小不敏感。C 语言标准对不同数据类型的数字范围设置了下界(这点在后面还将讲到),但是却没有上界。因为从 1980 年左右到 2010 年左右,32 位机器和 32 位程序是主流的组合,许多程序的编写都假设为图 2-3 中 32 位程序的字节分配。随着 64 位机器的日益普及,再将这些程序移植到新机器上时,许多隐藏的对字长的依赖性就会显现出来,成为错误。比如,许多程序员假设一个声明为 int 类型的程序对象能被用来存储一个指针。这在大多数 32 位的机器上能正常工作,但是在一台 64 位的机器上却会导致问题。
寻址和字节顺序、
对于 跨越多字节的程序对象,我们必须建立两个规则:这个 对象的地址是什么,以及在 内存中如何排列这些字节。在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。例如,假设一个类型为 int 的变量 x 的地址为 0x100,也就是说,地址表达式 &x 的值为 0x100。那么,(假设数据类型 int 为 32 位表示)x 的 4 个字节将被存储在内存的 0x100、0x101、0x102 和 0x103 位置。
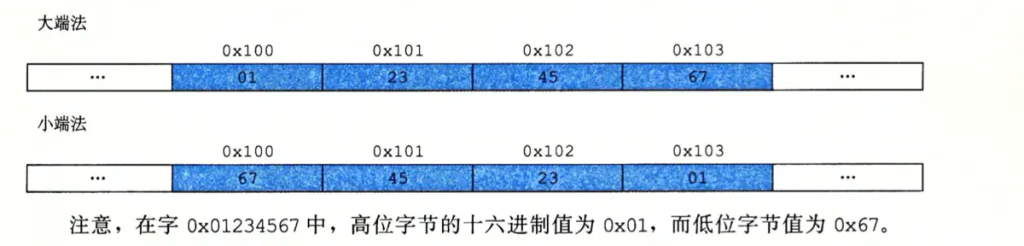
多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。某些机器选择在内存中按照从最低有效字节到最高有效字节的顺序存储对象,而另一些则按照从最高有效字节到最低有效字节的顺序存储。最低有效字节在地址最低处的方式,称为小端法。最高有效字节在地址最低处的方式,称为大端法。
排列一个对象的字节有两个通用的规则。考虑一个 w 位的整数,其位表示为 [xw-1,xw-2,…,x1,x0],其中 xw-1 是最高有效位,而 x0 是最低有效位。
假设变量 x 的类型为 int,4个字节大小,位于地址 0x100处,它的十六进制值为 0x01234567。地址范围 0x100 ~ 0x103的字节顺序依赖于机器的类型:
0x1234567的二进制为 0000 0001 0010 0011 0100 0101 0110 0111,每8位组成一个字节存储,所以总共位4个字节,转化为10进制为 1*2^0 + 1*2^1+1*2^2 + ...
注意,在字 0x01234567 中,高位字节的十六进制为 0x01,而低位有效字节值为 0x67。
大多数机器,windows,linux系统都是小端存储,而网络字节序是大端存储,所以在写socket网络编程时,需要把本地小端字节序转换成网络大端字节序。也有一些机器支持大端小端双端运行,可以随时切换运行模式。
Comments NOTHING